

自制操作系统(7):定时中断与sleep(),迁移内核到高半区
在上一节,我们成功地接管了键盘的中断,并重构了一些代码,实现键盘驱动,并实现了一个玩具Shell,今天我们要搞点硬核的东西,但是在此之前,我们先来点轻松的——实现一个sleep函数。
PIT(可编程间隔定时器)
PIT接收一个保持一定频率(1,193,182 Hz)的振荡器产生的输入信号,然后根据通过栅极输入(Gate Input)编程的配置,在不同的频道产生不同的栅极输出。PIT与键盘一样也是一种硬件,都可以通过IO端口与CPU进行数据互通。因此,我们可以通过IO端口对其进行编程。
PIT逻辑上有三个频道,0号频道连向了PIC芯片,所以它可以产生一个IRQ 0中断信号,也就是我们今天配置实现的定时中断;1号频道在早期的计算机被用于刷新储存在DRAM的电荷,现在已经被废弃;2号频道连向扬声器,可以用来配置产生不同频率的蜂鸣音(Beep sound)。
每个频道都可以配置不同的操作模式(Operation mode)。我们不需要了解每一个操作模式具体对应什么,我们直接来看今天要用到的2号操作模式,频率发生器 (Rate Generator)。
频率发生器 (Rate Generator)
频率发生器可以发生周期性的脉冲。切换到这个模式时,内置的计数器会在输入信号的下一个下降沿载入一个设定好的重载值,并把频道的输出调整为高电平,振荡器输入产生的震荡信号到下降沿时,PIT内置的计数器就会减1,计数减到1时,频道的输出就会被调整为低电平,减到0后又恢复为高电平,计数器被重新设置为重载值,如此往复,在输出端看来就是周期性的极窄负脉冲。IRQ的引脚默认是上升沿触发的,所以会在减为0(从低电平恢复到高电平)时触发IRQ 0中断。
IO端口
I/O port Usage
0x40 Channel 0 data port (read/write)
0x41 Channel 1 data port (read/write)
0x42 Channel 2 data port (read/write)
0x43 Mode/Command register (write only, a read is ignored)
(参考资料,OSDev Wiki)
Mode/Command register 的设置规则如下:
Bits Usage
7 and 6 Select channel :
0 0 = Channel 0
0 1 = Channel 1
1 0 = Channel 2
1 1 = Read-back command (8254 only)
5 and 4 Access mode :
0 0 = Latch count value command
0 1 = Access mode: lobyte only
1 0 = Access mode: hibyte only
1 1 = Access mode: lobyte/hibyte
3 to 1 Operating mode :
0 0 0 = Mode 0 (interrupt on terminal count)
0 0 1 = Mode 1 (hardware re-triggerable one-shot)
0 1 0 = Mode 2 (rate generator)
0 1 1 = Mode 3 (square wave generator)
1 0 0 = Mode 4 (software triggered strobe)
1 0 1 = Mode 5 (hardware triggered strobe)
1 1 0 = Mode 2 (rate generator, same as 010b)
1 1 1 = Mode 3 (square wave generator, same as 011b)
0 BCD/Binary mode: 0 = 16-bit binary, 1 = four-digit BCD
比如按上面所说,我需要让channel 0启用2号mode,那我的操作就应该是out 0x43 0b00110100。注意我这里把Access mode设置为了11,代表后面我在设置reload count时,会先在对应的channel输入低字节,再输入高字节。
现在的频率是1193182,我们设置reload count为11932,就能获得一个间隔大概为10ms的中断了。对应的操作是out 0x40 0x9c out 0x40 0x2e.
sleep函数实现
那么我们赶紧来开始写代码吧。
static volatile uint32_t ticks;
void timer_interrupt_handler(registers* /* regs */) {
++ticks;
hal_outb(0x20, 0x20); // EOI
return;
}
void pit_init() {
asm volatile ("cli");
ticks = 0;
register_interrupt_handler(32, timer_interrupt_handler);
hal_outb(0x43, 0x34);
hal_outb(0x40, 0x9c);
hal_outb(0x40, 0x2e);
}
void pit_sleep(uint32_t ms) {
uint32_t saved_ticks = ticks;
uint32_t ceilling_10ms = (ms + 9) / 10;
while (ticks - saved_ticks < ceilling_10ms) {
asm volatile ("hlt");
}
}
虽然上面说了那么多,但是代码还是相对简单的。
由此我们实现了一个精度为10ms的计时器。我们把它用在kernel_main上:
keyboard_init();
pit_init();
asm volatile ("sti");
...
char input[256];
while (1) {
...
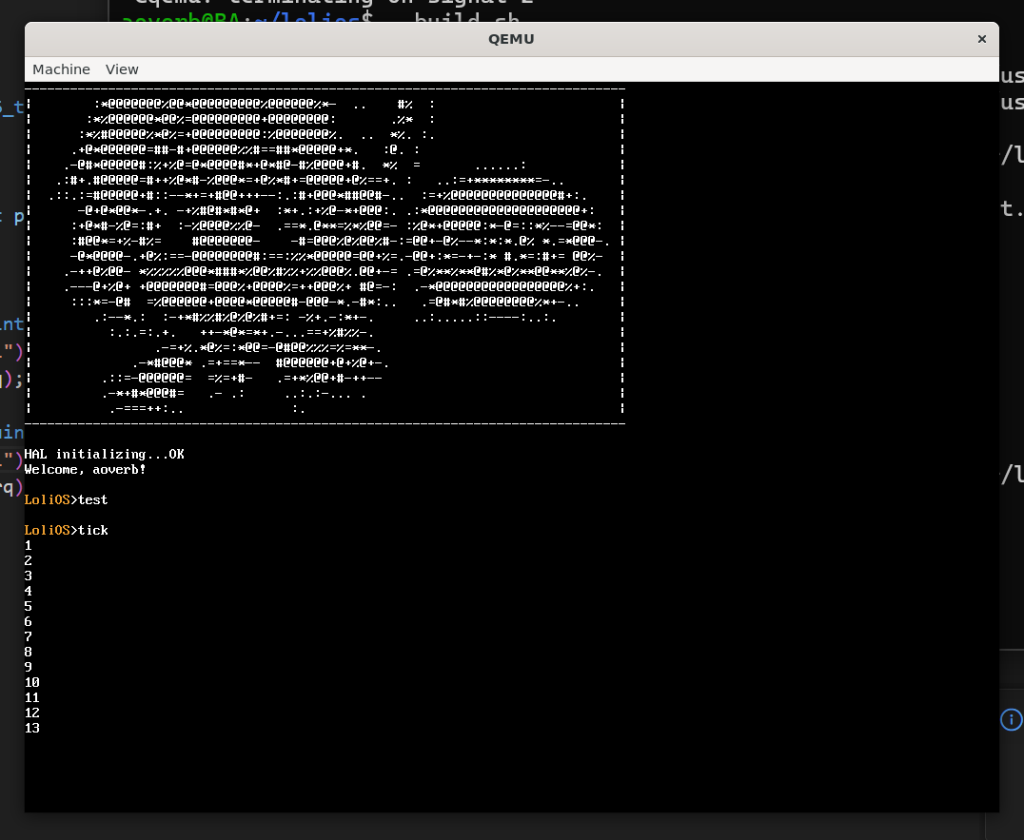
} else if (strcmp(input, "tick") == 0) {
uint8_t ticks = 0;
while (++ticks) {
printf("%d\n", ticks);
pit_sleep(1000);
}
}
...
}
风风火火启动测试,发现sleep没有生效,一顿排查之后发现是我在之前初始化pic时,把除了键盘的所有IRQ都屏蔽了。
我想,不应该在这里统一设置所有IRQ的屏蔽启动,应该交由硬件驱动决定,于是我把屏蔽/解除逻辑在pic.h封装了一层接口,实现如下:
void pic_enable_irq(uint8_t irq) {
uint16_t port;
uint8_t value;
if (irq < 8) {
port = 0x21;
} else {
port = 0xA1;
irq -= 8;
}
value = inb(port) & ~(1 << irq);
outb(port, value);
}
// 屏蔽特定 IRQ 线
void pic_disable_irq(uint8_t irq) {
uint16_t port;
uint8_t value;
if (irq < 8) {
port = 0x21;
} else {
port = 0xA1;
irq -= 8;
}
value = inb(port) | (1 << irq);
outb(port, value);
}
再通过hal.h统一封装:
void hal_enable_irq(uint8_t irq) {
asm volatile ("cli");
pic_enable_irq(irq);
}
void hal_disable_irq(uint8_t irq) {
asm volatile ("cli");
pic_disable_irq(irq);
}
这样我就能在我的驱动里面统一调用启停逻辑了:
void pit_init() {
asm volatile ("cli");
ticks = 0;
register_interrupt_handler(32, timer_interrupt_handler);
hal_outb(0x43, 0x34);
hal_outb(0x40, 0x9c);
hal_outb(0x40, 0x2e);
hal_enable_irq(0);
}
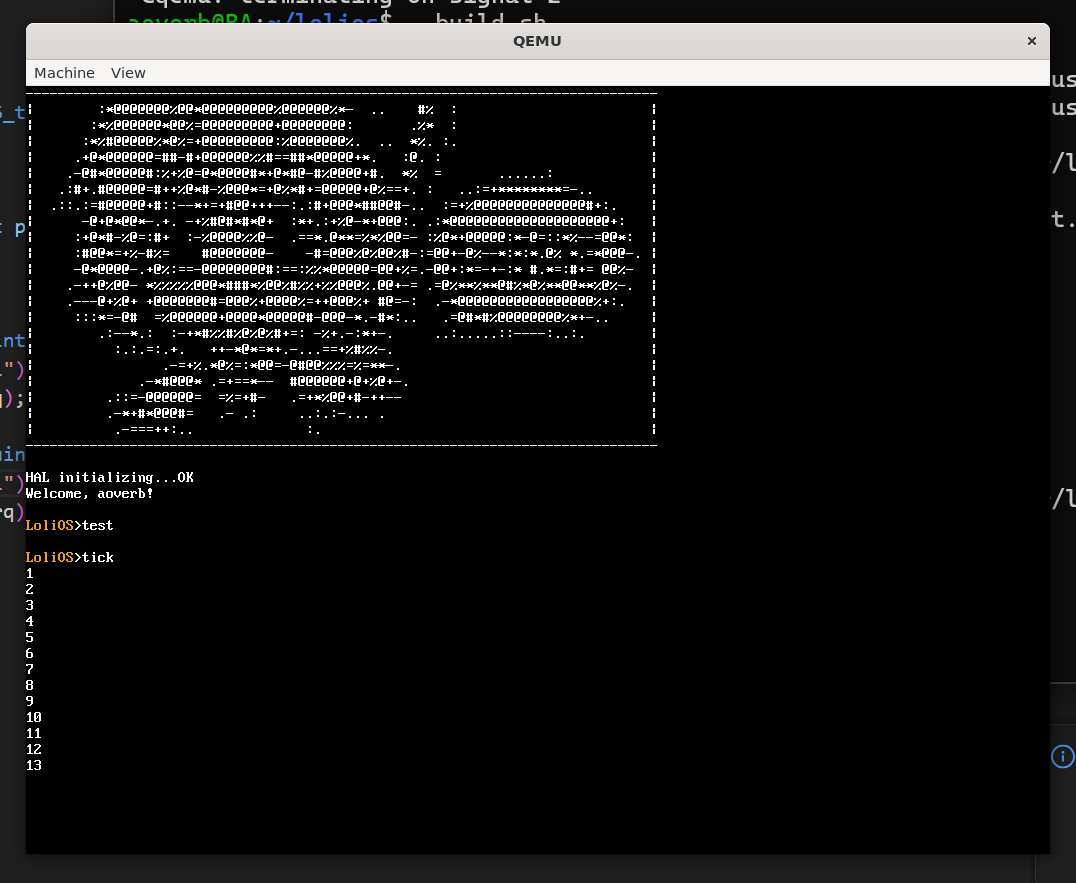
而且我们的sleep函数也正确工作了。但是我发现时间好像有误差,排查一通后,发现大概率是Qemu的问题。后面我们实机见真章吧。
长痛不如短痛:高半区内核
吭哧吭哧跑到这里,我才发现我漏掉了一件事情:高半区内核。笼统地说,高半区内核是指把内核加载在物理地址1MB左右的位置,但又映射到虚拟地址3GB左右的位置,而这种虚拟的映射依赖的是分页机制。我们从一开始其实一直都没打开分页机制,现在为了短痛,以及下面我用AI翻译的,OSDev Wiki所说的把内核映射在高半区的好处,我们来重构这部分的逻辑:
高半核(Higher Half Kernel)的优势:
更易于设置 VM86 进程:由于 1 MB 以下的内存区域属于用户空间,配置虚拟 8086 模式(VM86)变得更加简单。
更好的 ABI 兼容性:更普遍地说,用户级应用程序不再依赖内核空间占用多少内存。无论内核位于 $0xC0000000$、$0x80000000$ 还是 $0xE0000000$,你的应用程序都可以统一链接到 $0x400000$ 地址,这使得应用程序二进制接口(ABI)更加规范。
支持完整的 32 位寻址:如果你的操作系统是 64 位的,那么 32 位应用程序将能够使用完整的 32 位地址空间。
可使用“助记符”无效指针:可以使用类似于 $0xCAFEBABE$、$0xDEADBEEF$、$0xDEADC0DE$ 等具有特定含义的十六进制词汇作为无效指针标识。
修改linker.ld
我们在链接的时候,可以指定把数据加载在地址的哪个位置:
/* linker.ld */
ENTRY(_start)
SECTIONS
{
/* 内核从 1MB 处开始 */
. = 1M;
/* Multiboot 头必须在最前面 */
.text BLOCK(4K) : ALIGN(4K)
{
*(.multiboot)
*(.text)
}
/* 只读数据 */
.rodata BLOCK(4K) : ALIGN(4K)
{
*(.rodata)
}
/* 已初始化数据 */
.data BLOCK(4K) : ALIGN(4K)
{
*(.data)
}
/* 未初始化数据和栈 (BSS) */
.bss BLOCK(4K) : ALIGN(4K)
{
*(COMMON)
*(.bss)
}
}
我们目前还没开启分页,所以我们这段程序会被加载在线性地址1M的位置。还记得扁平化吗?扁平化下线性地址就是物理地址,所以我们实际上也加载在了1M的位置。
既然要加载在高半区,我们就按3GB用户程序+1GB内核程序的划分来划分两个区域。
我们希望在引导之后,达成这么一个环境:
1、我们的内核程序感知不到我们的物理内存实际上有多大,并认为自己被加载在了3GB的地址上,也就是我们进入了由分页机制的虚拟地址空间的假象之中;
2、实际上,我们的内核程序是被加载在了物理内存1MB的位置;
3、后面的内核指令、分配内存,从内核层面看到的地址,都是在虚拟地址空间的地址,实际上分配在物理地址的哪里,内核不用管。
ENTRY(_start)
SECTIONS
{
/* 内核将加载在 1MB 处 */
. = 0xC0100000;
.text ALIGN(4K) : AT(ADDR(.text) - 0xC0000000) /* 注意这里... */
{
*(.multiboot)
*(.text)
}
...
_kernel_end = . - 0xC0000000;
}
我们看到上面注释“注意这里”的地方,我们用到了一个AT指令,参数的运算结果是1MB周围,AT指令是我实际上要把这部分内容加载在哪的一个指令,而上面的. = 0xC0100000;则是设置一个对于指令的执行而言,我认为自己被加载到了内存的哪个地址的指令。
那么我们想想我们按这样的逻辑去链接会发生什么呢,GRUB按照我们的吩咐,将各个节加载在了物理内存1MB的周围,然后跳到ENTRY_POINT:
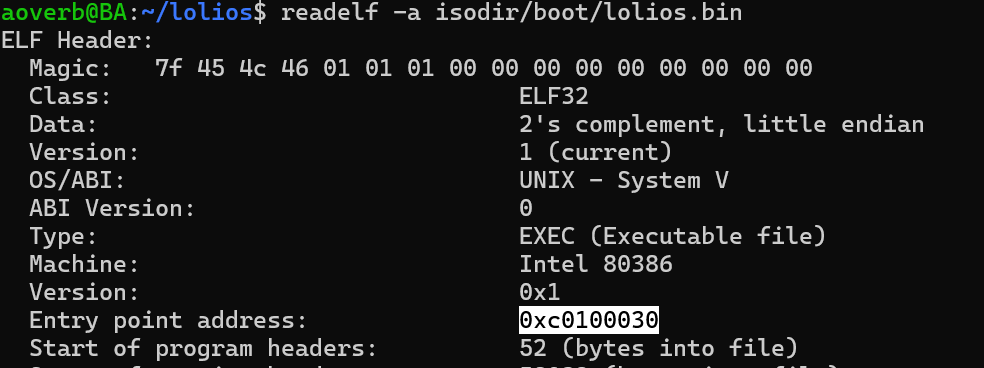
我们的入口点却在这里,悲剧了。
所以我们希望可以做点事情,先不要把我们的入口点搬到这个位置,我们先设置一个新的入口点,设置好分页机制后(具体来说,就是把3GB地址往后大概几MB的空间映射到物理地址1MB的位置),再跳入Kernel_main。我们不妨把这个新入口点叫做脚手架。
搭建脚手架
我们先来看看我们要怎么设置页表…慢着,但是首先什么是页表?什么是分页机制?
分页机制
之前我们不是介绍过分段机制吗,分段机制就是基址+逻辑地址,如果没有开启分页的话,这个计算的结果就是物理地址,而开启了分页的话,这个地址只能算作是虚拟地址,还需要经过一层转换才能转成物理地址。怎么转换呢?就是依赖分页机制里面的页表了。这里不打算展开介绍分页机制,可以参考经典的OSTEP阅读相关章节。
二级页表
我们采用二级页表的形式来管理分页,也就是1级页目录表+1级页表,虚拟地址划分是:
10位(PDE)+ 10位(PTE)+ 12位(偏移)
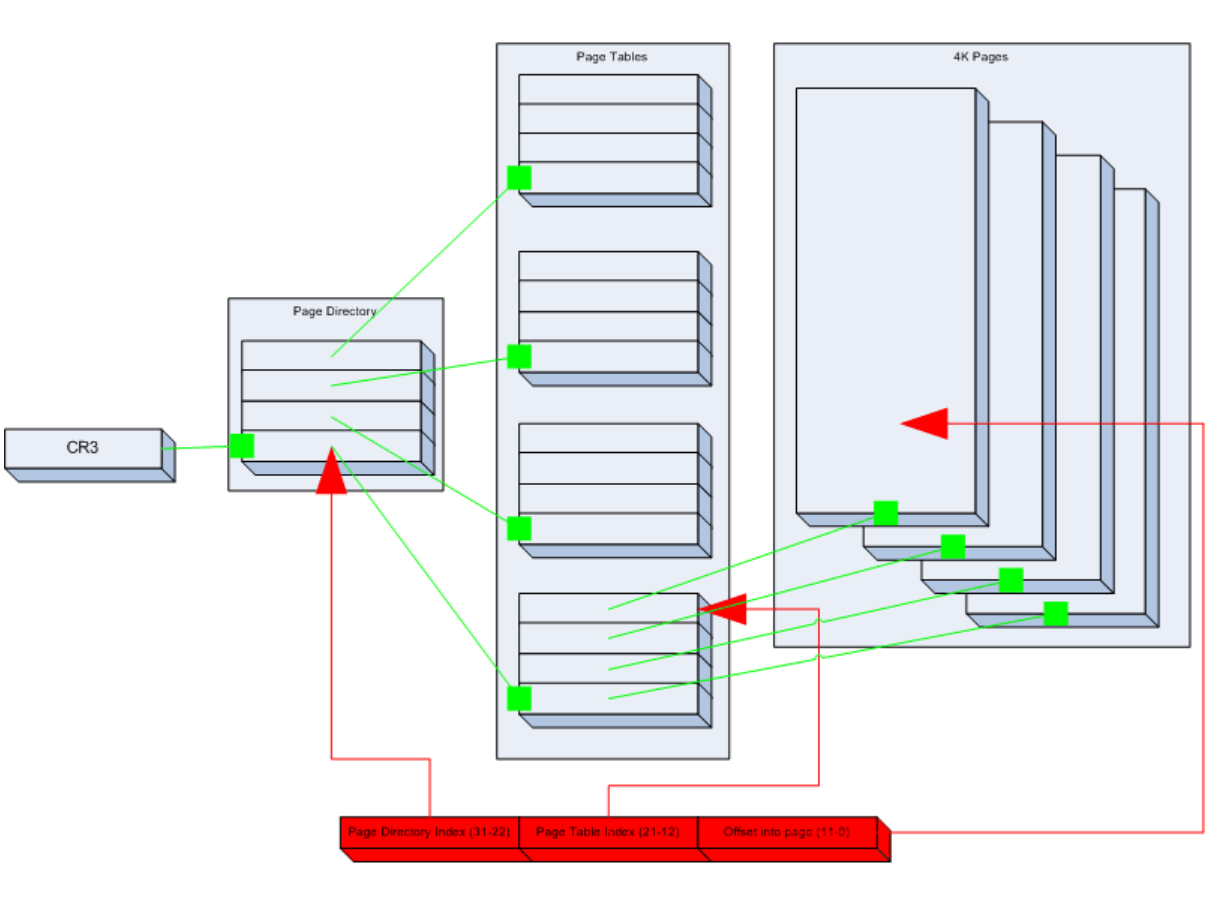
也就是,取PDE在页目录找到页目录项,再取PTE在页表找到页表项,再在对应的页里面根据偏移去获取数据/指令。
一开始的页目录被设置在CR3寄存器。
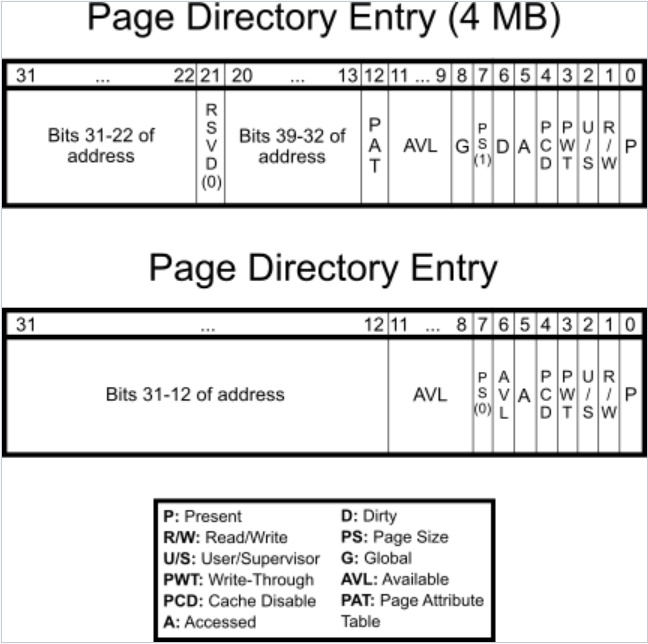

上面是放在内存空间里面的PDE和PTE的说明。
事不宜迟我们来改造下代码吧,首先从boot.s开始。
boot.s
.section .text
.global _start
.type _start, @function
_start:
mov $stack_top, %esp
/* 关键:将 Multiboot 信息结构的地址 (存在 ebx 中) 压入栈,传给 C++ */
push %ebx
call kernel_main
cli
hltLoop:
hlt
jmp hltLoop
我们不能把_start放在text段了,同样地,我们也不能一上来就call_main,我们要定义新的节.scaffold,那边才有我们的入口点:
/* boot.s */
.section .multiboot, "a" /* 这个很重要,有了这个我们在后面链接脚本的boot节才不会被乱排 */
.set ALIGN, 1<<0
...
.section .scaffold
.global _start
.type _start, @function
_start:
hlt
.section .text
.global _tokernelmain
.type _tokernelmain, @function
_tokernelmain:
mov $stack_top, %esp
/* 关键:将 Multiboot 信息结构的地址 (存在 ebx 中) 压入栈,传给 C++ */
push %ebx
call kernel_main
cli
hltLoop:
hlt
jmp hltLoop
关于上面的,如果没有这一行的话,会发生这样的情况:
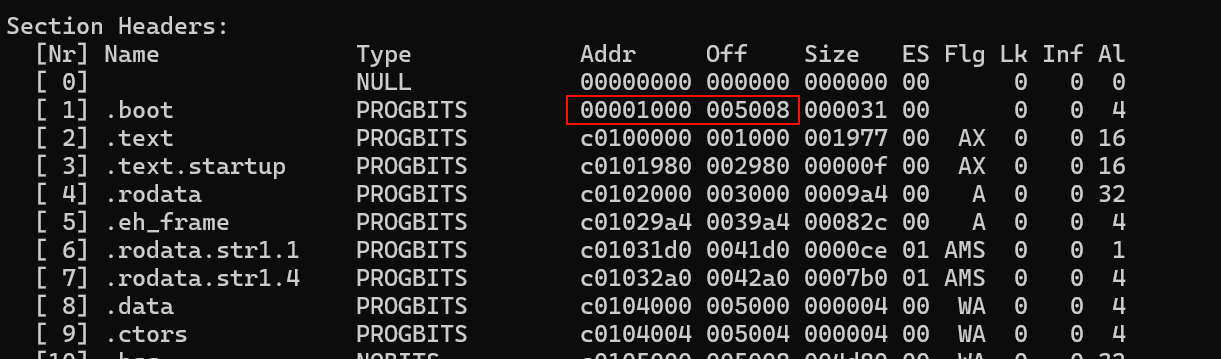
我们的虚拟地址是1000,但是文件偏移却是5008。因为ld认为我们不需要加载这个段(它不认识这个段)就把我们放到了文件里面靠后的位置。于是启动QEMU,multiboot的头就检测失败了。

加上之后偏移就正常了,显示为1M。
linker.ld如下:
ENTRY(_start)
SECTIONS
{
. = 1M;
.boot BLOCK(4K) : ALIGN(4K)
{
*(.multiboot)
*(.scaffold)
}
/* 内核将加载在 1MB 处 */
. += 0xC0000000;
.text ALIGN(4K) : AT(ADDR(.text) - 0xC0000000)
{
*(.text)
}
.rodata ALIGN(4K) : AT(ADDR(.rodata) - 0xC0000000)
{
*(.rodata)
}
.data ALIGN(4K) : AT(ADDR(.data) - 0xC0000000)
{
*(.data)
}
.bss ALIGN(4K) : AT(ADDR(.bss) - 0xC0000000)
{
*(COMMON)
*(.bss)
}
_kernel_end = . - 0xC0000000;
}
接下来我们得在.bss段定义页目录还有页表,还有很长的路要走。。。
定义页目录和页表
要定义页目录和页表,我们先来抽象地看下要怎么样去写。
页目录:
页目录需要有两个,第一个对应0x0 + 4MB的虚拟地址空间,第二个对应0xC0000000 + 4MB的虚拟地址空间。我们的内核还没有那么大,所以是够用的。
第一个放在第0x0/2^22 = 0项,第二个放在0xC0000000/2^22=768项。
也就是,我们需要在PDE[0]和PDE[768]填入两个PDE Entry,指向同一个页表(也就是同一批物理地址,因为我们设置PDE[0]的目的是为了开启分页之后,我们还在1MB附近的EIP不会找不到下一条指令的位置)。
可能可以是这么写:
.bss
.section page_directory:
long 第一个页目录项配置...
配置767个无效页目录项...
long 第768个页目录项配置...
页表:页表应该实现局部的扁平,也就是提供的基址与实际上指向的物理地址对应的位数是一样的。
为了映射4MB的空间,我们要把这个页表的1024个页表项都填满。
可能可以是这么写:
.bss
section page_table
循环 第一个扁平的页表项配置...
问了下ai,我的思路是对的,但是建议放在.data段而不是.bss段。
.section .data
.align 4096
page_table:
.set i, 0
.rept 1024
.long (i << 12) | 0x3
.set i, i + 1
.endr
.section .data
.align 4096
page_directory:
.long (page_table - 0xC0000000) + 0x3
.fill 767, 4, 0
.long (page_table - 0xC0000000) + 0x3
.fill 255, 4, 0
偷偷跟AI补了下课,好吧,至少我是先自己写了写,再给AI纠错写出来的。
加载CR3和CR0
看起来我们只要把page_directory的地址写进CR3就好,还有就是把CR0的PG位打开:
.section .scaffold
.global _start
.type _start, @function
_start:
cli
movl $page_directory, %eax
sub 0xC0000000,%eax
movl %eax, %cr3
movl %cr0, %eax
or $0x80000000, %eax
movl %eax, %cr0
movl $_tokernelmain, %eax
jmp *%eax
.section .text
.global _tokernelmain
.type _tokernelmain, @function
_tokernelmain:
mov $stack_top, %esp
/* 关键:将 Multiboot 信息结构的地址 (存在 ebx 中) 压入栈,传给 C++ */
push %ebx
call kernel_main
cli
hltLoop:
hlt
jmp hltLoop
写了一段这个代码,结果这次不是进去就冻结,而是进去就重启了。
通过加hlt,我发现有可能是cr0的问题。后面经过调试,发现是sub的锅直接改成:
cli
movl $(page_directory - 0xC0000000), %eax
movl %eax, %cr3
可过。但是后面还是重启了,好消息,是在CR0之后重启的,我们回到C函数了。(好想你!)
回到C
…坏消息,还不知道这回不知道是哪出的错,我们回到C代码:
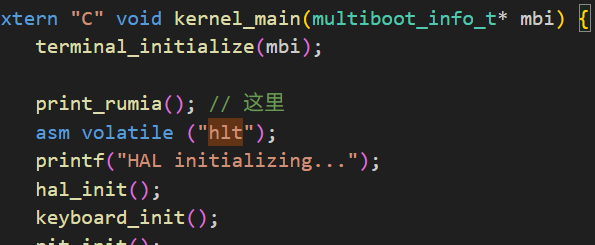
发现是这里的问题。怎么可能是rumia的问题呢?应该是我们的显存没有被正确映射…
显存重映射(暂定)
这里是个巨坑,因为我们已经回到了C,我们没有在.data段预留空间给显存的页目录项、页表…
我们不得不搞一块大页先用着,等后面实现kmalloc,再完善我们在C代码的分页机制。这意味着我们在未来很长一段时间都不得不有一段丑陋的代码…
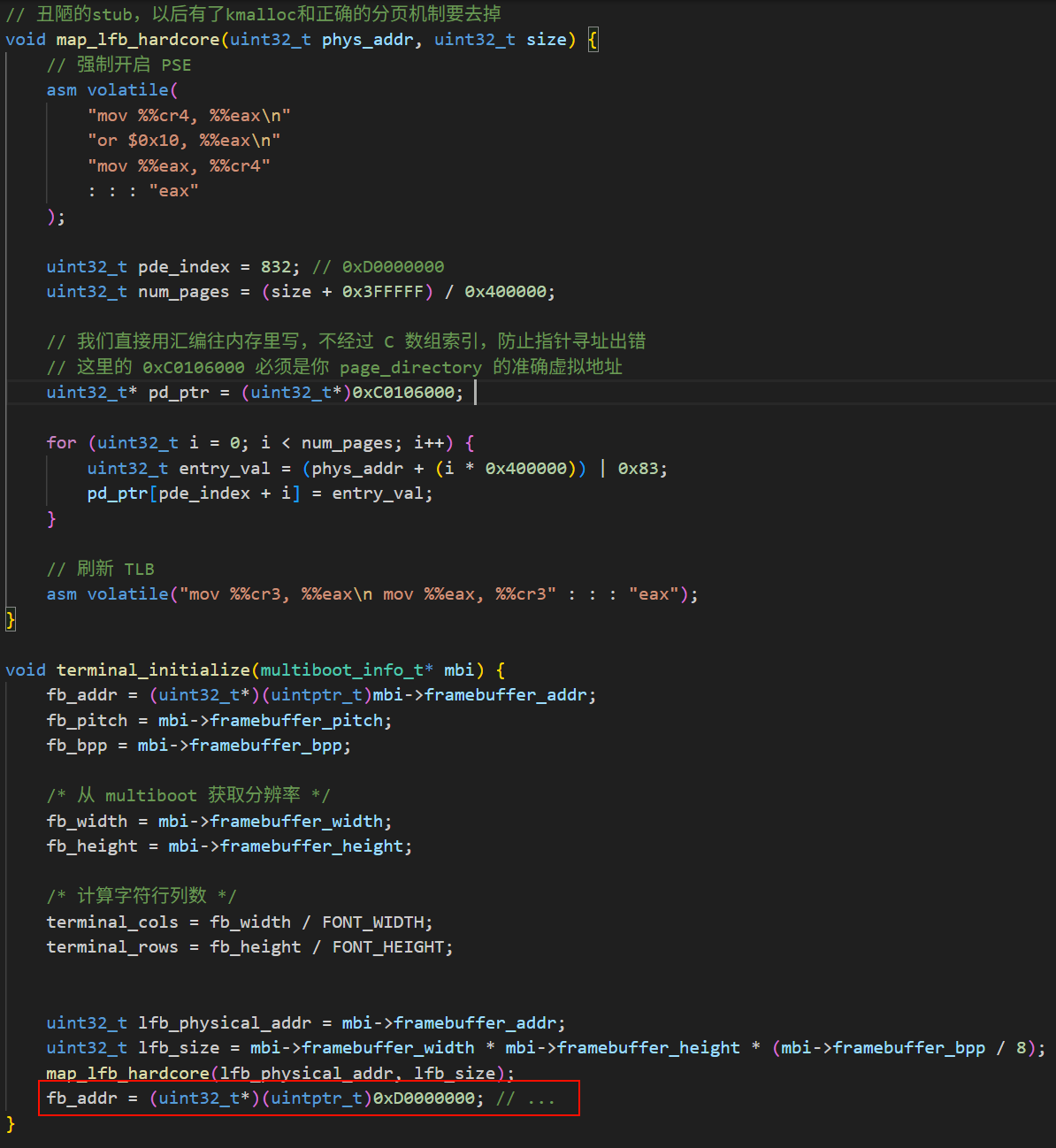
不管了,今天真的够累了…
验证
不过无论如何,我们先来打印个地址看看。

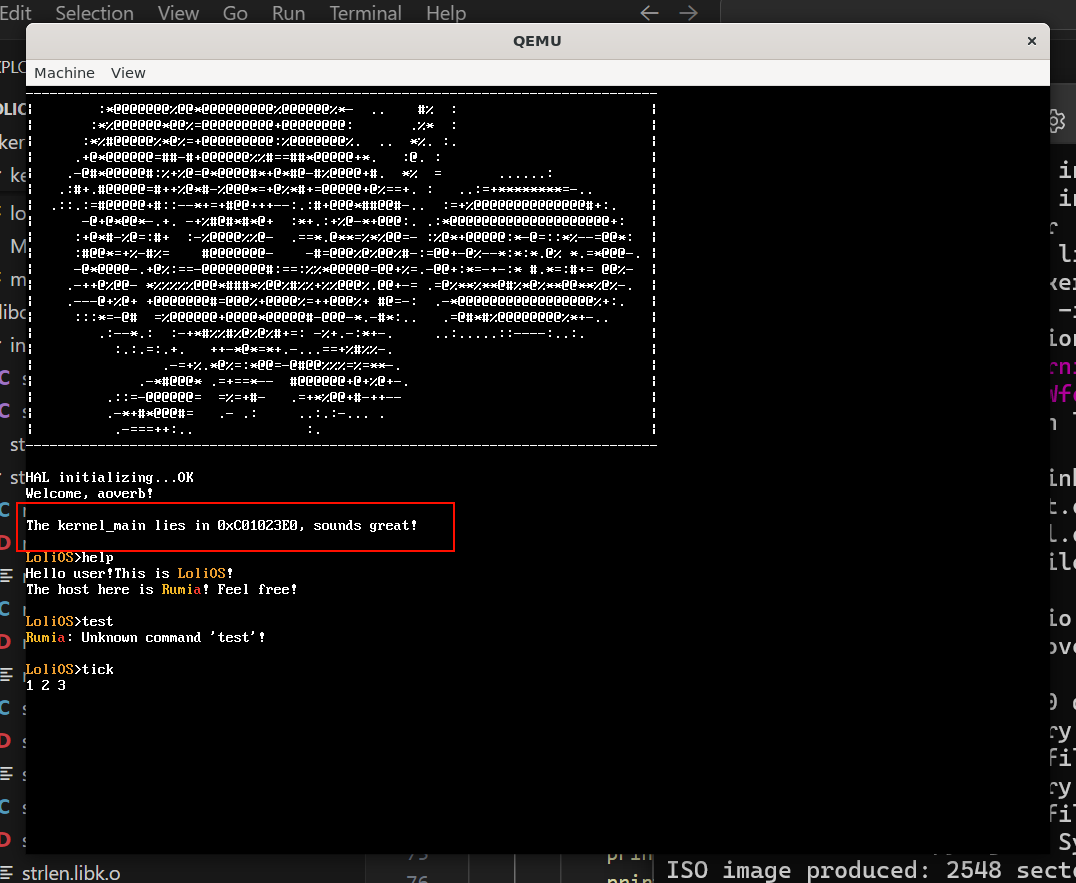
先不论我们的显存如何,我们的内核现在可是(虚拟地)活在高半区啊!
今天,我们小小看了一下PIT,然后实现了sleep函数,并且抱着长痛不如短痛的心态,重构了我们的内核,启用了分页机制,让我们的内核坐落于虚拟地址空间的高半区,虽然我们现在显存相关的页表比较拉跨,但是主要原因是:我们还没有实现kmalloc和动态的页分配!未来可期!
那么下一篇,我们将继续实现物理内存管理和虚拟内存管理!再然后,我们就可以尝试动态页分配,摆脱丑陋的代码了!
参与讨论
(Participate in the discussion)
参与讨论
没有发现评论
暂无评论