

自制操作系统(16):tarfs
上一节我们说完了抽象的vfs,这一节我们来讲讲具体的tarfs。
tar文件
tar文件其实早期是用于在磁带上组织文件的文件系统。所以解析这个文件很简单,既然文件的记录方式是顺序记录,我们可以用一次循环把里面的所有东西读取出来。我们以512字节为单位解析,解析一个头出来,获取大小,偏移512+大小字节,就是下一个头,直到读到空文件名。
typedef struct {
char name[100];
char filemode[8];
char owner_id[8];
char group_id[8];
char size[12];
char last_modified[12];
char checksum[8];
char type;
char name_of_link[100];
char ustar_indicator[6];
char ustar_ver[2];
char owner_name[32];
char group_name[32];
char dev_major_no[8];
char dev_minor_no[8];
char name_prefix[155];
char padding[12];
} tar_block;
static_assert(sizeof(tar_block) == 512, "tar_block must be 512 bytes!");
注意里面很多东西都基于8进制的字符串记录。所以,我们还需要准备一个把八进制的数字的字符串转成对应整数的函数。
uint32_t parse_octal(const char* s, int len) {
uint32_t val = 0;
for (int i = 0; i < len; i++) {
if (s[i] < '0' || s[i] > '7') break;
val = val * 8 + (s[i] - '0');
}
return val;
}
索引建立
因为一直顺序读取会比较耗时间,对于上面的tar头,里面的name和nameprefix,并不仅仅存放文件名,还记录了文件的完整路径,所以我们可以基于这一点,在mount的时候,基于里面的tar头建立树形索引,因为要建立文件名->inode_id的键值对,我还让claude帮我实现了unordered_map。
struct tar_inode {
tar_block* block = nullptr;
std::unordered_map<std::string, inode_id> child_inodes;
};
其中block记录的就是文件的数据,而如果是文件夹的话,我们遍历child_inodes就可以知道文件夹下所有的子inode id。
struct tarfs_data {
void* tar_addr;
uint32_t tar_size;
tar_inode* inodes[MAX_INODE_NUM];
uint32_t inode_cnt;
spinlock lock;
};
而在最原始的数据,我们会有一个inode_id -> tar_inode的映射数组。结合上面的child_inodes就能得出对应的子文件/目录。
创建目录树
构建目录树的思想是,先把根inode单独做出来,设置为0号,后面按顺序去读取tar文件的内容,对于每个文件,拆分成“父目录”和“当前文件”两块,如果父目录块不存在,就优先创建它,tar_block指针可以先设置为空,因为后面早晚会读到它,以父目录作为锚点,来创建当前文件块,并把它挂到父目录的子节点map中。
int construct_index(tarfs_data* tdata) {
// 构造根目录块
tdata->inodes[0] = new (kmalloc(sizeof(tar_inode))) tar_inode();
tar_inode* root = tdata->inodes[0];
root->block = reinterpret_cast<tar_block*>(kmalloc(sizeof(tar_block)));
root->child_inodes["."] = 0;
root->child_inodes[".."] = 0;
make_root_block(root->block);
tdata->inode_cnt++;
void* cur_addr = tdata->tar_addr;
tar_block* cur_block;
while ((uintptr_t)cur_addr - (uintptr_t)tdata->tar_addr < tdata->tar_size) {
cur_block = reinterpret_cast<tar_block*>(cur_addr);
if (cur_block->name[0] == '\0' && cur_block->name_prefix[0] == '\0') {
break;
}
if (checksum(cur_block) != parse_octal(cur_block->checksum, 8)) {
printf("corrupted block at offset %x\n",
(uint32_t)((uintptr_t)cur_addr - (uintptr_t)tdata->tar_addr));
// todo: cleaning
return -1;
}
if (cur_block->name_prefix[0] == '\0') {
strcpy(cur_block->name_prefix, cur_block->name);
int len = strlen(cur_block->name);
if (cur_block->name[len - 1] == '/') --len;
while(--len >= 0 && cur_block->name_prefix[len] != '/') cur_block->name_prefix[len] = '\0';
if (len >= 0) cur_block->name_prefix[len] = '\0';
int idx = 0;
int len_prefix = strlen(cur_block->name_prefix);
while (cur_block->name[idx] != '\0') {
cur_block->name[idx] = cur_block->name[idx + len_prefix + 1];
++idx;
}
cur_block->name[idx] = '\0';
}
tar_inode* dir = construct_inode_by_path(tdata, cur_block->name_prefix);
if (dir == nullptr) {
// todo: cleaning
return -1;
}
char key[128];
strcpy(key, cur_block->name);
// 如果最后一位是斜杠需要去掉
if (strlen(key) && key[strlen(key) - 1] == '/') {
key[strlen(key) - 1] = '\0';
}
if (*key) {
if (dir->child_inodes.find(key) == dir->child_inodes.end()) {
tar_inode* new_node = new (kmalloc(sizeof(tar_inode))) tar_inode();
dir->child_inodes[key] = tdata->inode_cnt;
tdata->inodes[tdata->inode_cnt++] = new_node;
if (tdata->inode_cnt > MAX_INODE_NUM) {
// todo: cleaning
return -1;
}
}
tdata->inodes[dir->child_inodes[key]]->block = cur_block;
tdata->inodes[dir->child_inodes[key]]->child_inodes["."] = dir->child_inodes[key];
tdata->inodes[dir->child_inodes[key]]->child_inodes[".."] = dir->child_inodes["."];
}
uint64_t file_size = parse_octal(cur_block->size, 12);
cur_addr = (uint8_t*)cur_addr + 512 + ((file_size + 511) / 512) * 512;
}
return 0;
}
里面用到的construct_inode_by_path,是会检测路径的每一层是否有对应的inode节点,如果没有,就先创建出来:
tar_inode* construct_inode_by_path(tarfs_data* tdata, const char* path) {
tar_inode* cur_node = tdata->inodes[0];
char fix_s[256];
char* s = fix_s;
uint32_t i = 0;
uint32_t prev_inode_id = 0;
while (i < 155 && path[i] != '\0') {
if (path[i] == '/') { ++i; continue; }
uint32_t s_len = 0;
while(i < 155 && path[i] != '/' && path[i] != '\0' && s_len < 255) {
s[s_len] = path[i];
++i;
++s_len;
}
s[s_len] = '\0';
if (s[0] == '\0') break;
if (cur_node->child_inodes.find(s) == cur_node->child_inodes.end()) {
if (tdata->inode_cnt > MAX_INODE_NUM) {
return nullptr;
}
uint32_t new_id = tdata->inode_cnt++;
cur_node->child_inodes[s] = new_id;
tar_inode* new_node = new (kmalloc(sizeof(tar_inode))) tar_inode();
new_node->block = nullptr;
new_node->child_inodes.clear();
new_node->child_inodes["."] = new_id;
new_node->child_inodes[".."] = prev_inode_id;
tdata->inodes[new_id] = new_node;
}
prev_inode_id = cur_node->child_inodes[s];
cur_node = tdata->inodes[cur_node->child_inodes[s]];
}
return cur_node;
}
其实这个逻辑相当简明,我有可能是把这部分代码写复杂了(主要在解析路径那一块,做得不甚优美)
open
我们可以在mount的时候执行上面的构建目录树的操作,目录树构建正常后,我们就可以考虑怎么来实现open接口了。
open接口本质上是要解析路径并转为inode id,由于我们知道根目录id,通过tar_inode的map一层层往下找就好了:
tar_inode* get_inode_by_path(tarfs_data* tdata, const char* path) {
tar_inode* cur_node = tdata->inodes[0];
char fix_s[256];
char* s = fix_s;
uint32_t i = 0;
while (i < 155 && path[i] != '\0') {
if (path[i] == '/') { ++i; continue; }
uint32_t s_len = 0;
while(i < 155 && path[i] != '/' && path[i] != '\0' && s_len < 255) {
s[s_len] = path[i];
++i;
++s_len;
}
s[s_len] = '\0';
if (s[0] == '\0') break;
if (cur_node->child_inodes.find(s) == cur_node->child_inodes.end()) {
return nullptr;
}
cur_node = tdata->inodes[cur_node->child_inodes[s]];
}
return cur_node;
}
read
static int tar_read(tarfs_data* data, uint32_t inode_id, uint32_t offset, char* buffer, uint32_t size) {
tar_inode* file_inode = data->inodes[inode_id];
// tar_dump_block(file_inode->block);
uint32_t file_size = parse_octal(file_inode->block->size, 12);
if (offset >= file_size) {
return 0; // EOF
}
if (offset + size > file_size) {
size = file_size - offset;
}
memcpy(buffer, (char*)file_inode->block + 512 + offset, size);
return size;
}
static int read(mounting_point* mp, uint32_t inode_id, uint32_t offset, char* buffer, uint32_t size) {
tarfs_data* data = reinterpret_cast<tarfs_data*>(mp->data);
SpinlockGuard guard(data->lock);
if (inode_id >= data->inode_cnt || !data->inodes[inode_id]) {
return -1;
}
return tar_read(data, inode_id, offset, buffer, size);
}
read按照tar结构的定义,在block开头偏移512字节作为起始地址,按照解析出来的block的大小来读取即可。
write
tar是只读文件系统,不支持读写,返回错误码即可。
readdir
这是做得比较挫的部分,每次传来一个offset,我们都不得不去从头遍历对应inode的map去得出目录项,这使得如果我们要遍历一个目录下的所有文件,需要O(n^2)的时间复杂度:但是对于现在的实现来说,聊胜于无了。
static int readdir(mounting_point* mp, uint32_t inode_id, uint32_t offset, dirent* out) {
tarfs_data* data = reinterpret_cast<tarfs_data*>(mp->data);
SpinlockGuard guard(data->lock);
if (inode_id >= data->inode_cnt) return -1;
tar_inode* dir_inode = data->inodes[inode_id];
auto& children = dir_inode->child_inodes;
if (offset >= children.size()) {
return 0;
}
auto it = children.begin();
for (uint32_t i = 0; i < offset; ++i) {
++it; // 非常拉跨
}
strncpy(out->name, it->first.c_str(), 255);
out->name[255] = '\0';
out->inode = it->second;
tar_inode* child = data->inodes[it->second];
if (child && child->block) {
out->type = child->block->type;
} else {
out->type = TYPE_DIR;
}
return 1;
}
由于tarfs的只读特性,也许我们也可以将map的每一项放到一个vector里,实现o(n)预处理,o(1)查询,但这是后话了。
效果
我们的shell解析成功,也正确执行了。
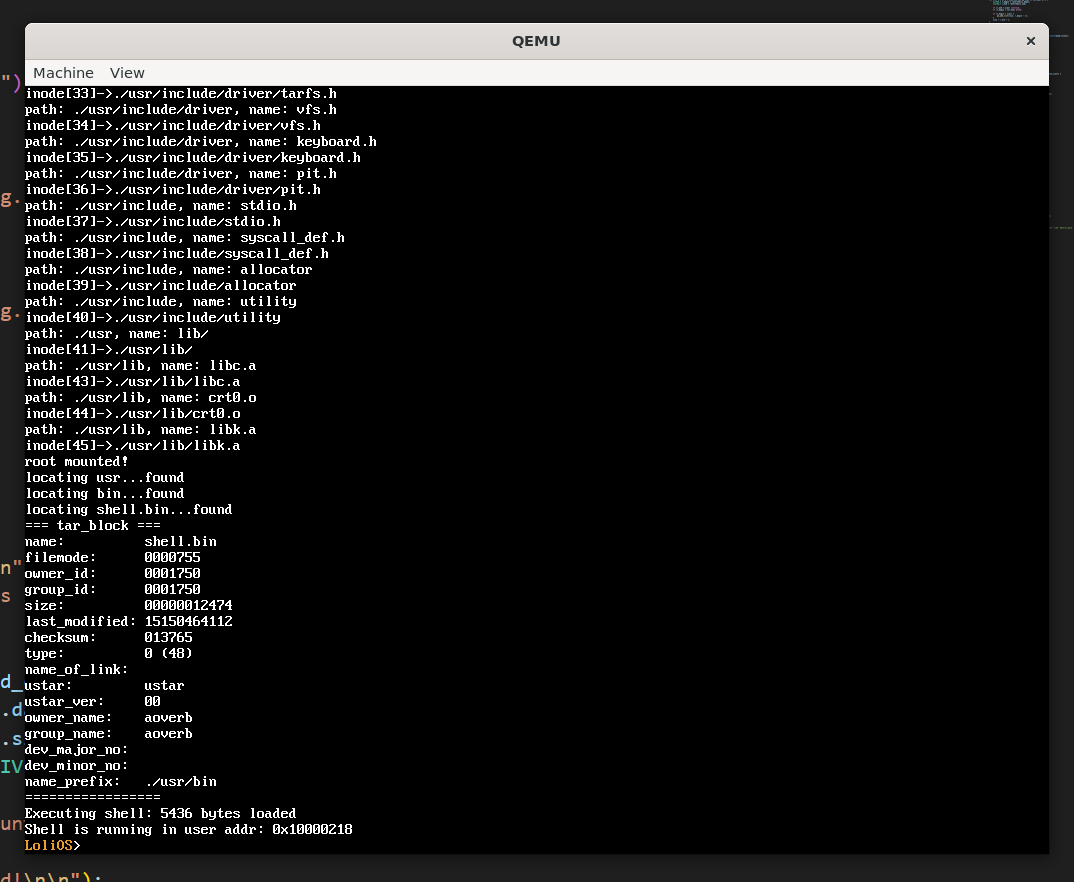
总结
这一节,我们实现了tarfs驱动,这使得我们的系统能够访问文件了!下一节,我们来看看怎么增强现有的shell,引入waitpid,并修复一些bug。
参与讨论
(Participate in the discussion)
参与讨论
没有发现评论
暂无评论