

自制操作系统(35):Ext2文件系统驱动——写入支持
上一节,我们实现了inode分配器,但有了inode分配器之后,我们只是能找到新的写入空间,里面的内容(即inode)还需要我们写一个新的函数来初始化。
更新inode元数据
inode包含两部分,一部分是元数据,另一部分是数据块索引。
我们先来实现一个更新inode元数据的函数:
set_inode_by_id
其实就是get_inode_by_id的改版,把buffer里面指定的inode内容改下,把这个缓存标成脏的就可以了:
static int set_inode_by_id(ext2_data* data, uint32_t id, const ext2_inode* in_inode) {
if (id == 0) return -1;
ext2_super_block& sb = data->sb;
uint32_t inodes_per_group = sb.s_inodes_per_group;
uint32_t idx = id - 1;
uint32_t group_idx = idx / inodes_per_group;
ext2_group_desc& gd = data->gdt[group_idx];
uint32_t inode_table_block_id = gd.bg_inode_table;
size_t inode_size = data->inode_size;
size_t block_size = data->dev->block_size;
uint32_t inodes_count_in_each_block = block_size / inode_size;
uint32_t idx_in_group = idx % inodes_per_group;
uint32_t block_idx = idx_in_group / inodes_count_in_each_block;
uint32_t offset = idx_in_group % inodes_count_in_each_block;
*reinterpret_cast<ext2_inode*>(get_cache_ptr(*data->cache_data,
inode_table_block_id + block_idx).get() + offset * inode_size) = *in_inode;
taint(*data->cache_data, inode_table_block_id + block_idx);
return 0;
}
和get_inode_by_id`几乎一模一样,唯一的区别就是方向反了——一个是从缓存读到临时buffer,一个是把传入的inode写进缓存然后标记脏。定位inode的逻辑是一样的。
向inode中插入一个数据块
我们再来实现一个向指定inode追加或插入数据块的函数。一开始本来想只写一个追加块的函数,后面发现,有一种文件叫稀疏文件,我去… 稀疏文件允许文件中间有空洞,也就是说逻辑块号对应的物理块可能不存在,读出来全是0。这种情况下只写追加就不够用了,我们需要能在任意位置插入一个物理块。
// 在insert_idx插入一个指定的物理块,如果这个地方已经有一个物理块,函数返回-1
// 如果replace为true,强制替换,注意,替换不会自动释放原有的物理块!
static size_t insert_block_in_inode(ext2_data* data, ext2_inode* inode,
uint32_t block_no, uint32_t insert_idx, bool replace = false);
思想跟read_block_in_inode是一样的,只不过没有它复杂——不用读数据,只需找到你要插入的位置位于哪级指针,分情况把 block_no 填进去。
代码又长又无聊… 我来摘一段二级间接指针的处理逻辑感受一下:
insert_idx -= data->block_num[1];
if (insert_idx < data->block_num[2]) {
if (inode->i_block[13] == 0) {
if (sb.s_free_blocks_count < 2) return -1;
inode->i_block[13] = block_alloc(data);
inode->i_blocks += block_size / SECTOR_SIZE;
memset(get_cache_ptr(*data->cache_data, inode->i_block[13]).get(), 0, block_size);
taint(*data->cache_data, inode->i_block[13]);
}
auto first_class_ptr = get_cache_ptr(*data->cache_data, inode->i_block[13]);
uint32_t* first_class = (uint32_t*)first_class_ptr.get() +
insert_idx / blkcnt_per_block;
if (*first_class == 0) {
if (sb.s_free_blocks_count == 0) return -1;
*first_class = block_alloc(data);
inode->i_blocks += block_size / SECTOR_SIZE;
memset(get_cache_ptr(*data->cache_data, *first_class).get(), 0, block_size);
taint(*data->cache_data, inode->i_block[13]);
taint(*data->cache_data, *first_class);
}
auto direct_ptr = get_cache_ptr(*data->cache_data, *first_class);
if (*((uint32_t*)direct_ptr.get() +
insert_idx % blkcnt_per_block) != 0 && !replace) return -1;
*((uint32_t*)direct_ptr.get() + insert_idx % blkcnt_per_block) = block_no;
taint(*data->cache_data, *first_class);
inode->i_blocks += block_size / SECTOR_SIZE;
return 0;
}
逻辑就是:如果中间级的指针块还没分配,就分配并清零;然后在对应的槽位写入block_no。每一级都要注意缓存用完要taint标记脏,i_blocks也要累加。三级间接更是三重嵌套,看代码就懂了,不展开了。
目录项插入
struct ext2_dir_entry {
uint32_t inode;
uint16_t rec_len;
uint8_t name_len;
uint8_t file_type; // 1=普通文件, 2=目录, 7=符号链接 ...
char name[]; // 不以 \0 结尾!
};
目录项本质上就是把这几项填好,写入一个目录inode的数据块里面。
有一个新的问题:一个目录的数据块里可能已经有了几个目录项,每个目录项的rec_len指明到下一个目录项的偏移。我们要插入新条目时,得找一个既有条目后面有足够剩余空间的缝隙。需要一个新函数add_entry_to_dir来做这件事:
int add_entry_to_dir(ext2_data* data, uint32_t dir_inode_no, uint32_t entry_inode_no,
uint8_t file_type, const char* name) {
ext2_inode dir_inode;
if (get_inode_by_id(data, dir_inode_no, &dir_inode) < 0) return -1;
uint16_t rec_len = sizeof(entry_inode_no) + sizeof(rec_len) +
sizeof(file_type) + sizeof(uint8_t) + strlen(name);
rec_len = (rec_len + 3) / 4 * 4; // 四字节对齐
const size_t block_size = data->dev->block_size;
uint32_t block_num = (dir_inode.i_size + block_size - 1) / block_size;
// 遍历所有已有块,找缝隙
for (int i = 0; i < block_num; ++i) {
uint32_t read_offset = 0;
int phys_block_no = get_phys_block_no_in_inode(data, &dir_inode, i);
auto cache_ptr = get_cache_ptr(*data->cache_data, phys_block_no);
while (read_offset < block_size) {
ext2_dir_entry* entry = reinterpret_cast<ext2_dir_entry*>(
cache_ptr.get() + read_offset);
size_t old_entry_actual_len = (8 + entry->name_len + 3) / 4 * 4;
if (entry->rec_len == 0) break;
if (entry->rec_len > old_entry_actual_len &&
entry->rec_len - old_entry_actual_len >= rec_len) {
// 找到了缝隙!
ext2_dir_entry* new_entry = (ext2_dir_entry*)(
cache_ptr.get() + read_offset + old_entry_actual_len);
new_entry->file_type = file_type;
new_entry->inode = entry_inode_no;
memcpy(new_entry->name, name, strlen(name));
new_entry->name_len = strlen(name);
size_t remain_len = entry->rec_len - old_entry_actual_len;
entry->rec_len = old_entry_actual_len;
new_entry->rec_len = remain_len;
taint(*data->cache_data, phys_block_no);
return 0;
}
read_offset += entry->rec_len;
}
}
// 找不到可写的地方,分配新块写入
int new_blk = block_alloc(data);
if (new_blk < 0) return -1;
insert_block_in_inode(data, &dir_inode, new_blk, block_num);
auto cache_ptr = get_cache_ptr(*data->cache_data, new_blk);
memset(cache_ptr.get(), 0, block_size);
ext2_dir_entry* new_entry = (ext2_dir_entry*)cache_ptr.get();
new_entry->file_type = file_type;
new_entry->inode = entry_inode_no;
memcpy(new_entry->name, name, strlen(name));
new_entry->name_len = strlen(name);
new_entry->rec_len = block_size; // 整块都是我的
taint(*data->cache_data, new_blk);
dir_inode.i_size += block_size;
set_inode_by_id(data, dir_inode_no, &dir_inode);
return 0;
}
这里还有一个细节:我们缺少一个获取inode指定逻辑块对应物理块的函数。之前的 read_block_in_inode是把数据读到buffer,但现在我们需要知道物理块号本身,因为要在上面直接改目录项。所以有了get_phys_block_no_in_inode:
static int get_phys_block_no_in_inode(ext2_data* data, ext2_inode* inode, uint32_t idx) {
// 和 read_block_in_inode 类似的遍历逻辑,但只返回物理块号
if (idx < 12) return inode->i_block[idx];
// ... 各级间接指针查找
}
这个函数对于空洞块会返回0,调用方需自行处理。
open 与 create
接下来我们可以来实现 open 了。根据VFS的设计,open 既要负责打开已有文件,也要负责创建新文件。
static int open(mounting_point* mp, const char* path, uint8_t mode) {
if (strlen(path) >= 256) return -1;
ext2_data* data = (ext2_data*)mp->data;
if (path[0] != '/') return -1;
char par_path[256];
char name[256];
split_path(path, par_path, name);
if (name[0] == '\0') return -1;
int inode_no = relative_lookup(data, ROOT_INODE_NO, path);
if (inode_no > 0) {
if (mode & O_TRUNC) {
truncate(mp, inode_no, 0);
flush_all_block(*data->cache_data);
flush_metadata(data);
}
return inode_no;
}
if (inode_no <= 0 && (mode & O_CREATE) == 0) return -1;
return create(data, par_path, name, FILE_TYPE_FILE);
}
逻辑很简单:ernel/driv
1. 把路径拆成父目录路径和文件名;
2. 尝试查找这个路径对应的inode;
3. 如果找到了且带O_TRUNC标志,就把文件截断到0;
4. 如果没找到且带了O_CREATE`,就调用create创建。
create函数负责实际的新文件创建:
static int create(ext2_data* data, const char* path, const char* name, int type) {
int path_inode_no = relative_lookup(data, ROOT_INODE_NO, path);
if (path_inode_no <= 0) return -1;
int new_inode_no = inode_alloc(data);
if (new_inode_no <= 0) return -1;
ext2_inode new_inode;
init_inode(new_inode, type);
set_inode_by_id(data, new_inode_no, &new_inode);
add_entry_to_dir(data, path_inode_no, new_inode_no, type, name);
flush_all_block(*data->cache_data);
flush_metadata(data);
return new_inode_no;
}
流程:
1. 找父目录inode;
2. 分配一个新inode号;
3. 用init_inode初始化inode(设置模式、链接计数等);
4. 把inode写回磁盘缓存;
5. 在父目录中添加目录项;
6. 刷新所有脏块和元数据。
这里 init_inode 也需要说一下:
void init_inode(ext2_inode& inode, uint8_t type) {
memset(&inode, 0, sizeof(inode));
inode.i_mode = (type == FILE_TYPE_DIR) ? 0x4000 | 0755 : 0x8000 | 0644;
inode.i_links_count = (type == FILE_TYPE_DIR) ? 2 : 1;
}
目录的链接计数初始为2(.和父目录的..引用),普通文件为1。
write
write 函数是写入功能的核心,逻辑和 read 类似但方向相反:
static int write(mounting_point* mp, uint32_t inode_id, uint32_t offset,
const char* buffer, uint32_t size) {
ext2_data* data = (ext2_data*)mp->data;
const size_t block_size = data->dev->block_size;
ext2_inode inode;
if (get_inode_by_id(data, inode_id, &inode) < 0) return -1;
uint32_t begin_block = offset / block_size;
uint32_t end_block = (offset + size + block_size - 1) / block_size;
int written = 0;
for (int i = begin_block; i < end_block; ++i) {
int phys_block;
if ((phys_block = get_phys_block_no_in_inode(data, &inode, i)) == 0) {
phys_block = block_alloc(data);
if (phys_block < 0) return -1;
insert_block_in_inode(data, &inode, phys_block, i);
}
auto cur_block = get_cache_ptr(*data->cache_data, phys_block);
size_t write_size = (block_size - cur_offset) < size ?
(block_size - cur_offset) : size;
memcpy(cur_block.get() + cur_offset, buffer, write_size);
taint(*data->cache_data, phys_block);
buffer += write_size; size -= write_size;
written += write_size; cur_offset = 0;
}
uint32_t new_end = offset + written;
if (new_end > inode.i_size) inode.i_size = new_end;
set_inode_by_id(data, inode_id, &inode);
flush_all_block(*data->cache_data);
flush_metadata(data);
return written;
}
细节:
1. 先算出需要写哪些块;
2. 对每个逻辑块,如果对应物理块不存在(空洞或文件末尾),就分配新块并插入;
3. 通过get_cache_ptr拿到块的缓存直接修改;
4. 修改完标记脏;
5. 如果写入后的偏移超出了文件大小,更新i_size;
6. 最后统一刷新所有脏块和元数据。
这里要注意的是,我一开始实现的时候遇到了一个诡异的现象:
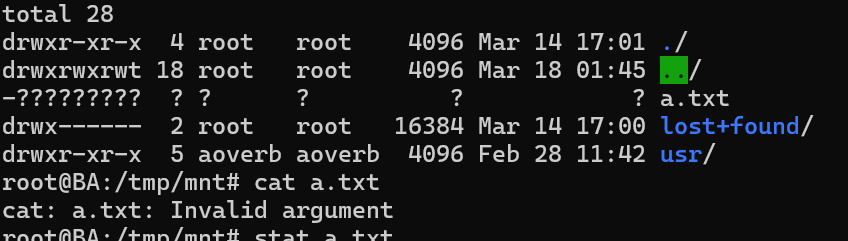
如图,在 moeos 中创建了a.txt并写回磁盘镜像后,切到 WSL 上用ll一看,好家伙,a.txt的文件详细信息全变成了问号。排查了半天,发现是bitmap操作的时候,char类型转换上溢导致写入分配到了不该分配的inode,导致Linux 读 inode 时解析出来的全是非法值。具体是细节已经记不清了,总之所有bitmap操作加uint8_t强转后就正常了。
truncate
文件截断函数truncate支持缩小和扩大两种情况:
- 缩小:释放多余的物理块,清理间接指针树,清零最后一个块的尾部残留数据
- 扩大:只需要更新i_size,实际物理块由 write 按需分配
释放块的时候要递归释放间接块树:
static void free_block_tree(ext2_data* data, uint32_t inode_no, int depth) {
if (inode_no == 0) return;
if (depth > 0) {
auto cache_ptr = get_cache_ptr(*data->cache_data, inode_no);
for (int i = 0; i < data->dev->block_size / 4; ++i) {
free_block_tree(data, *(reinterpret_cast<uint32_t*>(cache_ptr.get()) + i), depth - 1);
}
}
block_free(data, inode_no);
}
depth=0 是直接指针块,直接释放;depth>0 要先递归释放子块再释放自己。
unlink
删除文件分两步:
1. 从父目录中移除目录项remove_entry_from_dir;
2. 减少inode的链接计数,如果减到0就释放所有数据块并释放inode。
移除目录项时,如果要删除的条目是块中的第一个,就把它的inode置0标记删除;如果不是第一个,就把它的rec_len合并到前一个条目:
if (last_offset == read_offset) {
entry->inode = 0; // 我就是第一项,标记删除
} else {
ext2_dir_entry* last_entry = ...;
last_entry->rec_len += entry->rec_len; // 合并到前一项
}
释放inode的ext2_unlink要处理链接计数:
if (--inode.i_links_count != 0) {
set_inode_by_id(data, inode_id, &inode); // 还有人引用,更新计数即可
return 0;
}
// 没人引用了,释放所有物理块
for (int i = 0; i < 12; ++i) free_block_tree(data, inode.i_block[i], 0);
free_block_tree(data, inode.i_block[12], 1);
free_block_tree(data, inode.i_block[13], 2);
free_block_tree(data, inode.i_block[14], 3);
memset(&inode, 0, sizeof(inode));
set_inode_by_id(data, inode_id, &inode);
inode_free(data, inode_id);
mkdir
创建目录比创建文件复杂一些,因为要处理.和..:
static int mkdir(mounting_point* mp, const char* path) {
// ... 路径检查、防重名、防非法名字 ...
int new_inode_id = inode_alloc(data);
ext2_inode inode;
init_inode(inode, FILE_TYPE_DIR);
add_entry_to_dir(data, dir_inode_id, new_inode_id, FILE_TYPE_DIR, name);
set_inode_by_id(data, new_inode_id, &inode);
add_entry_to_dir(data, new_inode_id, new_inode_id, FILE_TYPE_DIR, ".");
add_entry_to_dir(data, new_inode_id, dir_inode_id, FILE_TYPE_DIR, "..");
// 父目录链接计数+1
ext2_inode par_inode;
get_inode_by_id(data, dir_inode_id, &par_inode);
++par_inode.i_links_count;
set_inode_by_id(data, dir_inode_id, &par_inode);
flush_all_block(*data->cache_data);
flush_metadata(data);
return 0;
}
步骤:
1. 拆分路径得到父目录和目录名;
2. 分配新inode,初始化为目录类型;
3. 在父目录中添加新目录的条目;
4. 在新目录中添加.条目(指向自己)和..条目(指向父目录);
5. 父目录的链接计数+1;
6. 刷新。
注册
最后,把这些函数注册到ext2_fs_operation结构体里:
void init_ext2fs() {
ext2_fs_operation.mount = &mount;
ext2_fs_operation.open = &open;
ext2_fs_operation.read = &read;
ext2_fs_operation.write = &write;
ext2_fs_operation.close = &close;
ext2_fs_operation.opendir = &opendir;
ext2_fs_operation.readdir = &readdir;
ext2_fs_operation.closedir = &closedir;
ext2_fs_operation.stat = &stat;
ext2_fs_operation.unlink = &unlink;
ext2_fs_operation.mkdir = &mkdir;
ext2_fs_operation.truncate = &truncate;
// ...
register_fs_operation(FS_DRIVER::EXT2FS, &ext2_fs_operation);
}
效果
编译运行,我们先试试创建文件和写入内容:
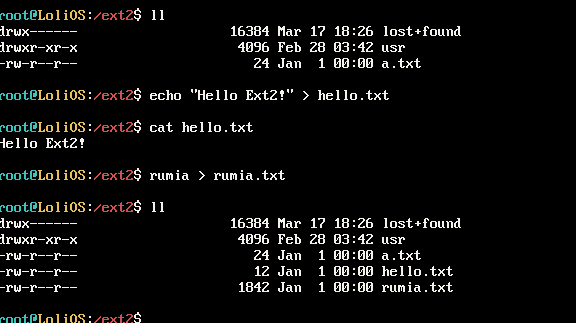
成功了!可以看到我们用shell和管道能力创建了新文件hello.txt和rumia.txt,写入内容后再读出来,数据完全正确。
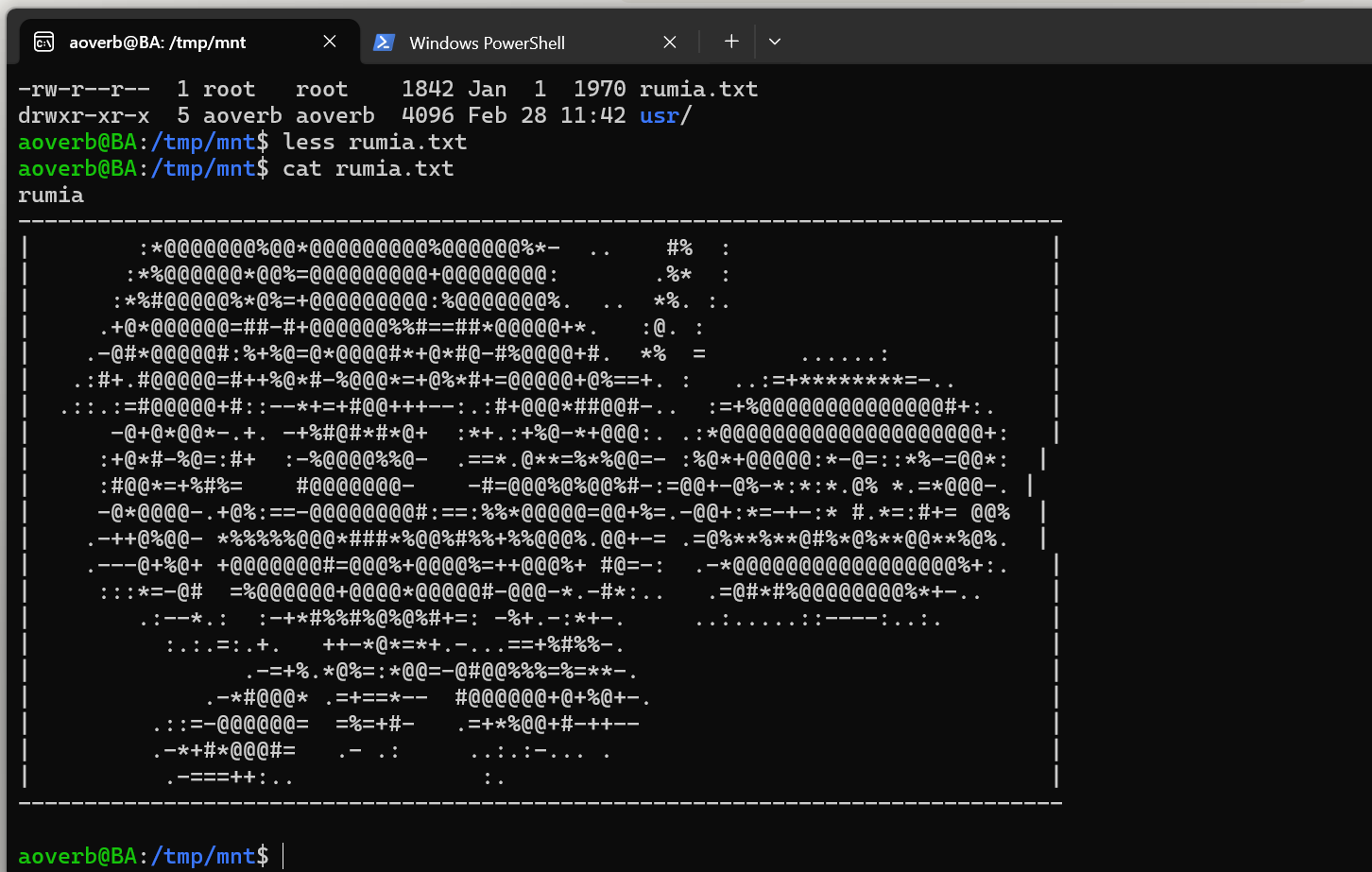
在挂载的镜像里面直接查看我们的新文件,可以看到已经被写回了。
至此,我们已经成功实现了可写入的Ext2驱动!现在我们的操作系统可以在Ext2文件系统上自由地创建、写入、读取、删除文件和目录了。
总结
我们实现了Ext2中写入相关的大部分功能,这说明我们的系统已经具备了持久化存储的能力!
我们的Ext2文件系统之旅在此告一段落。下一节,让我们来移植一个文本编辑软件——kilo。
参与讨论
(Participate in the discussion)
参与讨论
没有发现评论
暂无评论