

原文:vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
框架
本文先介绍了LLM遇到的吞吐量困境,并进一步指出其瓶颈在于内存,因为对于每个正在计算的序列,计算输出需要把庞大的,Token转化而来的Key、Value张量存放到GPU的内存(称为KV Cache),而KV Cache的长度本身又会动态变化,当有多个序列并行计算时,内存会有碎片化的问题。这个问题,与操作系统里段式内存管理遇到的碎片困境是高度相像的。因此vLLM团队从操作系统的虚拟内存机制借鉴了经验,提出了分页Attention,也就是将KV Cache分页管理,减少内存碎片来提高内存利用率,进而提升吞吐量的方法。进一步地,他们还借鉴了Copy on write等概念。经实验,这种方法要比SOTA方法提升数倍的吞吐量。
核心
为什么KV Cache成为吞吐量的瓶颈?
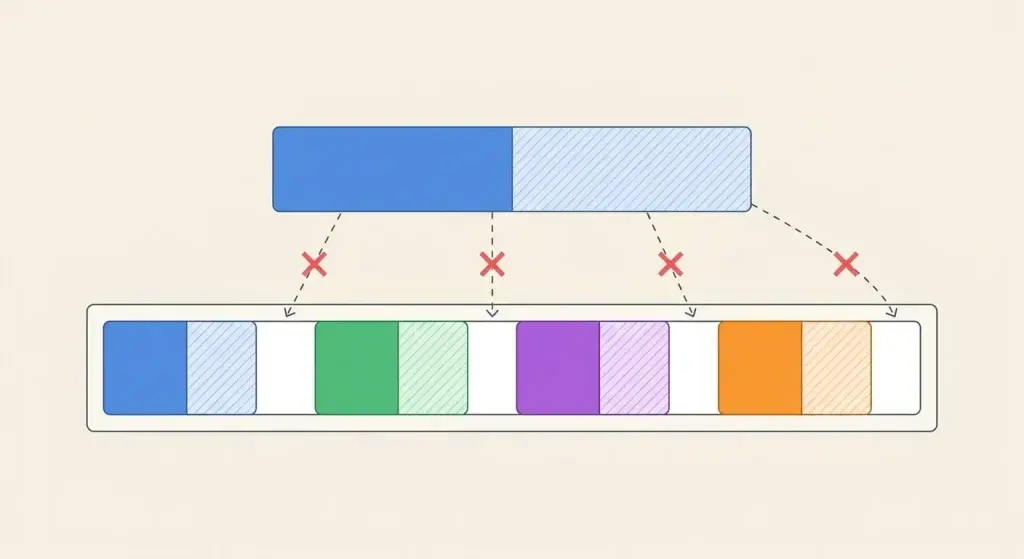
KV Cache中的KV是指Key、Value张量,是构造Attention的时候,从Token转化而成的两个必不可少的张量,首先,这样的张量很大;其次,当前序列Token的数量随着输出也会发生变化,这就造成了每个序列占用庞大的内存空间,且该占用量动态变化。这种情况跟操作系统的内存管理困境是非常相像的:给每个序列预留的空间太多,会造成浪费(就像操作系统中申请了过多的堆空间而不去使用),这被称为内部碎片问题;即使序列之外的可用空间总和足够容入新的序列,因为现有的序列把这些空间切成了几个碎片,可能也会因为无法申请一段连续的内存而无法容入新的序列,这被称为外部碎片问题。
图中,浅色部分为内部碎片,白色部分为外部碎片。
这种内存空间利用率不足的问题据称,浪费了60%-80%的内存空间!由此可见,碎片问题成为了吞吐量的瓶颈问题。
PagedAttention: 页式管理内存
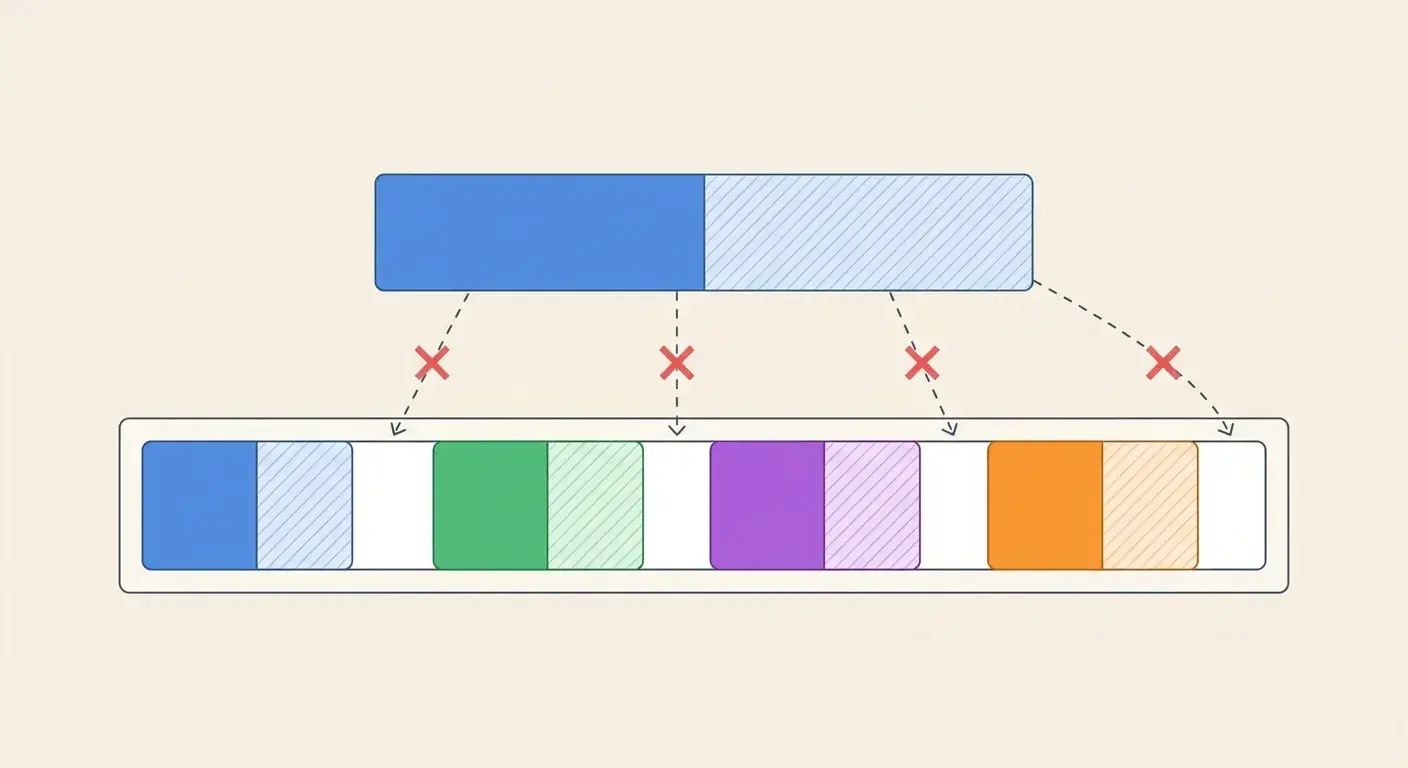
而实际上,我们可以用PagedAttention去解决这个问题——物理上,我们不去申请连续的内存,而是把内存预先分成一块块,逻辑上把这些块状的物理内存串联起来,减少外部碎片,提高物理内存的利用率。从KV Cache的视角,自己是被放在一块块的逻辑内存上的,而这种从逻辑内存到物理内存的映射关系,则由Block Table去维护。
这样的物理分块、逻辑映射的做法,不仅减少了内存碎片,还使内存块共享成为可能。
块大小(block size)的选择相当重要,这是空间 vs 查表开销的 trade-off,vLLM 默认 16。
Memory Sharing与写时复制
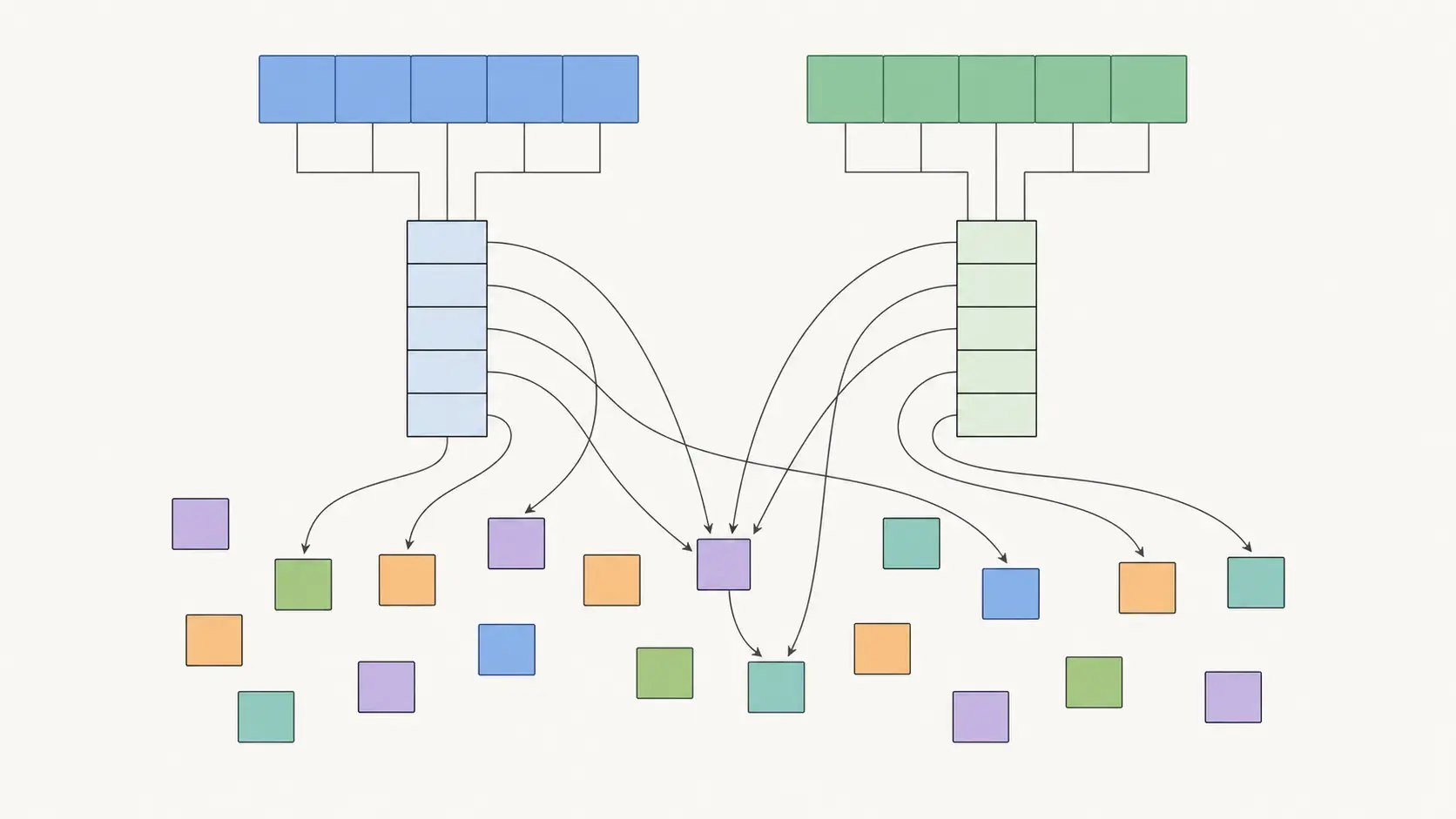
在parallel sampling(一个输入输出多种答案)、beam search(计算概率每次取top k)场景,都可以通过共享内存来提高效率(据称减少了55%的开销)。物理块会在其元数据中维护一个引用计数来确保共享的内存不会出现泄漏问题。进一步地,他们还借用了Cow(Copy on write,写时复制机制),当共享内存被修改时,会再在内存中复制一份当前写入块的副本,重新在Block Table建立新的映射关系,再进行写入修改操作。
与OS的概念类比
| PagedAttention概念 | OS概念 |
|---|---|
| Sequence | 进程 |
| PagedAttention | 分页内存 |
| KV Cache | 进程占用的内存 |
| Block | 页 |
| Physical Block | 物理内存页 |
| Logical Block | 虚拟内存页 |
| Block Table | 页表 |
| Parallel sampling | 有点类似Fork |
| 外部碎片、内部碎片 | 一致 |
| 写时复制 | 一致 |
关键误解
页表
我最开始认为页表是所有内存共用的,里面存的是从逻辑块号到物理块号的映射。实际上,每个序列都会有一个页表,页表是一个数组,本身就维护了连续的逻辑块的关系,所以逻辑块也不是像链表那样串联起来的,它们的关系是连续的。同样地,我一开始以为引用计数维护在页表上,实际上是在物理块的元数据中进行维护。
疑问
1、逻辑内存中,内存块的串联由谁来、怎么管理?从逻辑内存到物理内存的转化要怎么做?
串联管理:见关键误解中的”页表“。
转化:
上面提到每个 sequence 有一个 block table,索引是 logical block id(按 sequence 中 token 顺序排列:第 0、1、2、… 个 block),值是 physical block id。
访问 sequence 中第 N 个 token 的 KV 时:
- logical_block_idx = N // block_size(比如 block_size=16,token 35 在第 2 个 logical block)
- offset = N % block_size(在 block 内的偏移,token 35 是 offset 3)
- physical_block_id = block_table[logical_block_idx](查表)
- 实际访存 physical_blocks[physical_block_id][offset]
这跟OS里面的虚拟地址转换十分类似!只不过在OS里面,是MMU硬件帮我们做了这一步。
2、beam search(计算概率每次取top k)场景为什么会用到Memory sharing?
每一步保留 top-k 个候选序列,下一步每个候选生成vocab_size个延续,再保留top-k。关键是k个候选共享一个相同的prompt前缀,由此就可以做到多个分支只保存一份相同的prompt前缀的KV Cache。
参与讨论
(Participate in the discussion)
参与讨论
发现2条评论
vLLM vs SGLang 性能实测5090、Qwen2.5 7B、吞吐与 p99 延迟 – A/B's Blog
2026年06月03日 23:59获取中...
[…] 相同的地方:两套引擎共享两个核心思想:continuous batching和pagedAttention。 […]
从 static batching 到 continuous batching:一文看懂 LLM 推理吞吐量优化 – A/B's Blog
2026年05月30日 20:53获取中...
[…] [PagedAttention 是什么?从 OS 分页机制看懂 vLLM 的吞吐量优化](https://zmoe.com/3008… […]