

原文链接:How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
GPU很贵,所以我们要尽可能地提高它的利用率。为了提高利用率,业界提出了很多方法,本文提出的continuous batching便是其中一种,它是基于static batching的一种改进,能提高大模型推理的吞吐量,还能减少p50延迟(即中位数延迟)。我们先来介绍一下什么是batching。
batching
想象多个人在使用同一块GPU的场景,每个人都在不同的时间段输入自己的prompt(提示词)到大模型服务,然后等待大模型来给它输出答案。而这个过程发生了什么呢?基本可以分为两个部分,第一个部分是把提示词prefill(预填充),计算出提示词的KV-Cache放到显存里面,第二个部分是decode,根据最后一个token计算出一个Q向量,并利用显存中的权重和KV-Cache中的向量去做计算,在末尾生成出一个新的token,周而复始,直到输出完毕。
Prefill和decode的不对称性
前面介绍的过程,透露出单次会话的两个部分有不同的瓶颈:prefill可以利用GPU的并行计算能力,一次性加载大量token的嵌入向量,计算出批量的KV-Cache放在显存,所以prefill部分更受制于GPU的算力;decode部分,每次只计算单个token的Q、K、V向量,但是计算需要加载模型权重,KV-Cache也随生成变长,并且:
1、对于计算卡,普遍而言,将显存中的数据读入计算单元的速度,是要远低于计算单元做浮点运算的速度的(你不能直接在显存里面做计算,就像CPU也必须要把内存中的数值读进寄存器,而不是直接在内存做计算一样);
2、权重的加载占用了大部分的显存带宽,所以decode部分,受制于数据总线的读取速度,也就是显存带宽;此外KV-Cache随生成变长,也会逐步增加每步要读的数据量。
一句话总结就是,通常情况下,prefill受制于算力,decode受制于显存带宽。
并发场景的批处理——从static batching说起
那放在上面所说的多人用一块GPU的场景,按照上面的过程,是否有什么可以优化的地方呢?当然是有的,同样是利用GPU的并行计算能力,可以把多个会话的计算请求N个合并到一批,这样做的话一些权重相关的资源可以只经过计算单元一遍,却能产生N个计算结果,吞吐量提升了N倍!
Orca的研究还在这个基础上发展出了selective batching,可以把prefill/decode两种不相干的计算中,不依赖序列本身的独立部分在一次迭代里做并行计算,而不能独立计算的部分(如依赖attention计算出attention输出)会按序列拆开,分别计算,使得这两种计算可以在某种程度上并行。不过这是题外话了,这里不做展开。
如果这样做的话,同一批的处理过程就会像是下面这样:
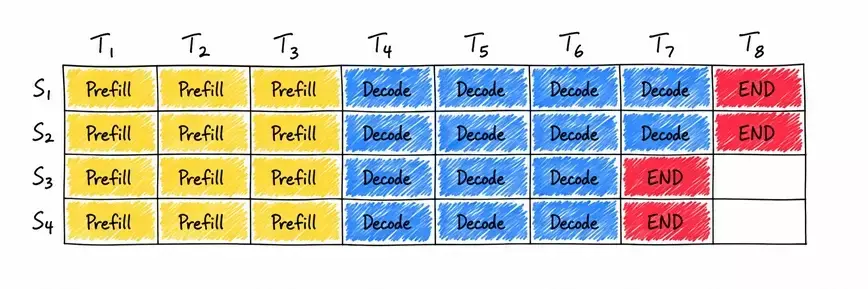
每列代表一次迭代,每行代表一批里面的一个序列,黄色代表prefill,蓝色代表decode,红色代表当前序列的结束token,标志着当前序列完成了生成。
看起来不错。但是如果我们再看看下面的例子呢?
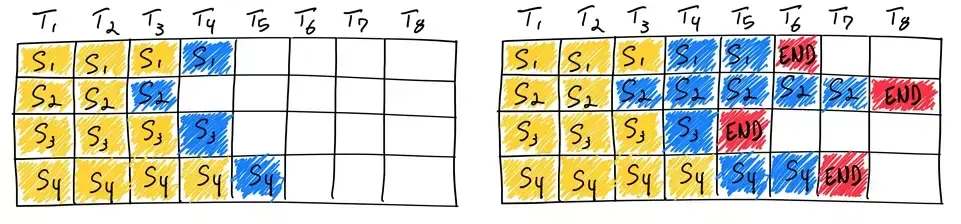
来看这个各个序列相差悬殊的例子。对了,忘了介绍白色的格子——代表被浪费的计算资源。
可以看到,static batching存在木桶效应,整批的结束时间受制于占用时间最长的序列,而在此之前除它之外所有序列已经完成了生成,这造成了批处理中槽位的浪费。这种浪费,与每个序列的prompt长度、生成序列长度的随机性相关。
怎么改进呢?聪明的你或许想到了答案——在同一批的一个序列结束的时候,紧接着开启一个新的序列的生成,不就好了吗?是的,但这仍然不是continuous batching的精细阐述。我们用“序列结束”这种事件来描述,纯粹是以结果的表象来描述方法论,这失去了static batching原有的迭代概念,失去了每个迭代中各个序列的状态描述,所以,continuous batching更精细的阐述应该是:
将static batching以批为粒度的调度策略,细化到了continuous batching中以迭代为粒度的调度策略。
continuous batching
下面的图片,就是一个continuous batching的直观阐述。在红色块之后,新的序列进入该批,与旧的序列并行计算:
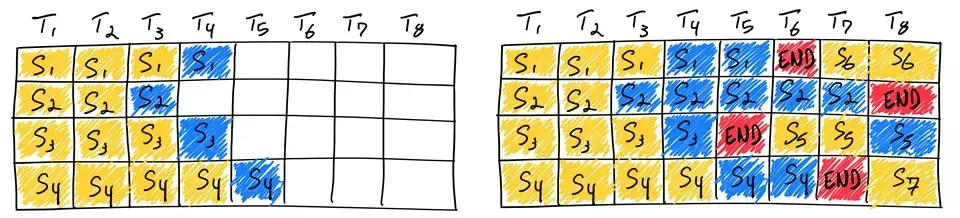
有新的序列进入并行计算,批处理槽位不白白浪费,每次权重流式进入计算单元时能参与计算的token增多,因此吞吐量提升了。
可是,凭空想象要比实现简单,要做到continuous batching,是要解决几个问题的。
举几个例子:需要支持在同一个迭代进行不同类型的计算——幸好上面提到的selective batching解决了这个问题;需要重新实现一个调度策略,不仅是把按批进行的调度粒度调整成按迭代,还要考虑显存总量不足和碎片化的问题,TTFT(Time to the first token,生成第一个token所需的时间,可以理解为响应时间)与TPOT(Time per output token,生成每个token平均需要的时间) 的权衡…
原文如此:”Reality is a bit more complicated.“
与PagedAttention形成的组合拳
在continuous batching提出之后,vllm为了实现continuous batching,对其中的一些实现难点进行了探索,包括预留上下文带来的显存浪费,显存碎片,最终提出了PagedAttention这种策略:它借用了操作系统的虚拟内存和页式内存管理概念,使得KV-Cache可以在显存中不连续分布和访问。有了PagedAttention,continuous batching更能在高并发场景下发挥作用。
有关PagedAttention的介绍可以查看我的历史文章:
[PagedAttention 是什么?从 OS 分页机制看懂 vLLM 的吞吐量优化](https://zmoe.com/3008.html)
Benchmark
吹了那么久,文章也做了一些实证上的数据验证。我们这里不对数据陈述本身去做记录(没有意义,可以去读原文),来说说它采取的一些方法。
选用的指标
我们可以看到它选用了两个指标:吞吐量和延迟,都是与用户体验和GPU利用率相关的指标。
相关参数:单张 A100-40GB 上跑 OPT-13B。
吞吐量
按照之前的说法,应该是序列之间的长度差越大,两种batching的差距越明显,于是文章在算吞吐量时,设置了统一的prefix长度512,然后按照指数分布,在最大生成token32、128、512、1536四种场景中去做生成速度的测量,结果果然是随着最大生成token数量越大,对于static batching,同一个批次,不同序列的上下文差距越大,两种batching的差距就逐渐被拉开了。文章标题的23倍,也是对于里面hugging face最朴素的static batching实现来进行对比的,而对于SOTA,则是3倍。
在其中,我们还可以看到vllm的PagedAttention的优化在continuous batching的纵向对比中也很明显,因为vllm对于decode无需预先分配显存(ahead-of-time),而是按需实时分配显存(just-in-time)。
延迟
延迟选用的采样策略相比于吞吐量,输入改成了均匀分布,并结合了泊松过程来模拟请求到达。
得益于优良的排队延迟优化,continuous batching的P50延迟也大大优于static batching的P50延迟。
总结
相对于static batching,continuous batching要带来更饱和的GPU使用率,这有效提高了并发场景下的GPU吞吐量和降低了排队延迟,当然continuous batching自身的实现,也需要提及许多概念和问题,如prefill和decode的不对称性,selective batching作为迭代内不同任务并行执行的前提,以迭代为粒度的调度策略,以及应运而生的pagedAttention等等,掌握了这些概念,continuous batching为何具有如此大的优化,并不难理解。
参与讨论
(Participate in the discussion)
参与讨论
发现1条评论
vLLM vs SGLang 性能实测5090、Qwen2.5 7B、吞吐与 p99 延迟 – A/B's Blog
2026年06月03日 23:59获取中...
[…] 相同的地方:两套引擎共享两个核心思想:continuous batching和pagedAttention。 […]