
AI
-

2026年6月16日 25 次浏览
-
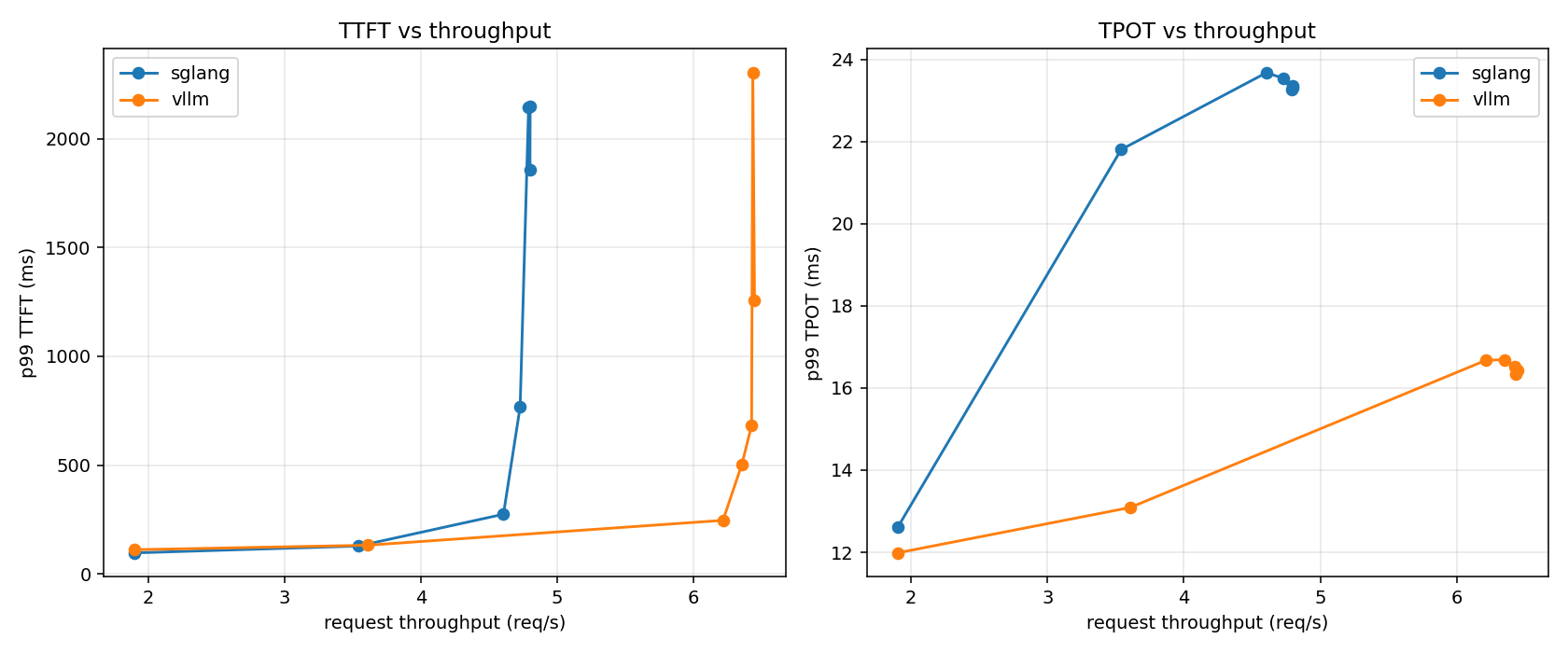
vLLM vs SGLang 性能实测:5090、Qwen2.5 7B、吞吐与 p99 延迟
2026年6月3日 68 次浏览
-
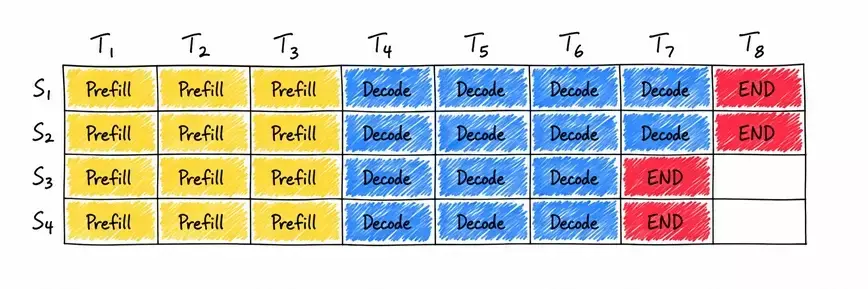
从 static batching 到 continuous batching:一文看懂 LLM 推理吞吐量优化
2026年5月30日 53 次浏览
-

2026年5月29日 42 次浏览
-

从Attention讲到如何计算你家的显卡能塞下多大的大模型
2026年5月28日 49 次浏览
-
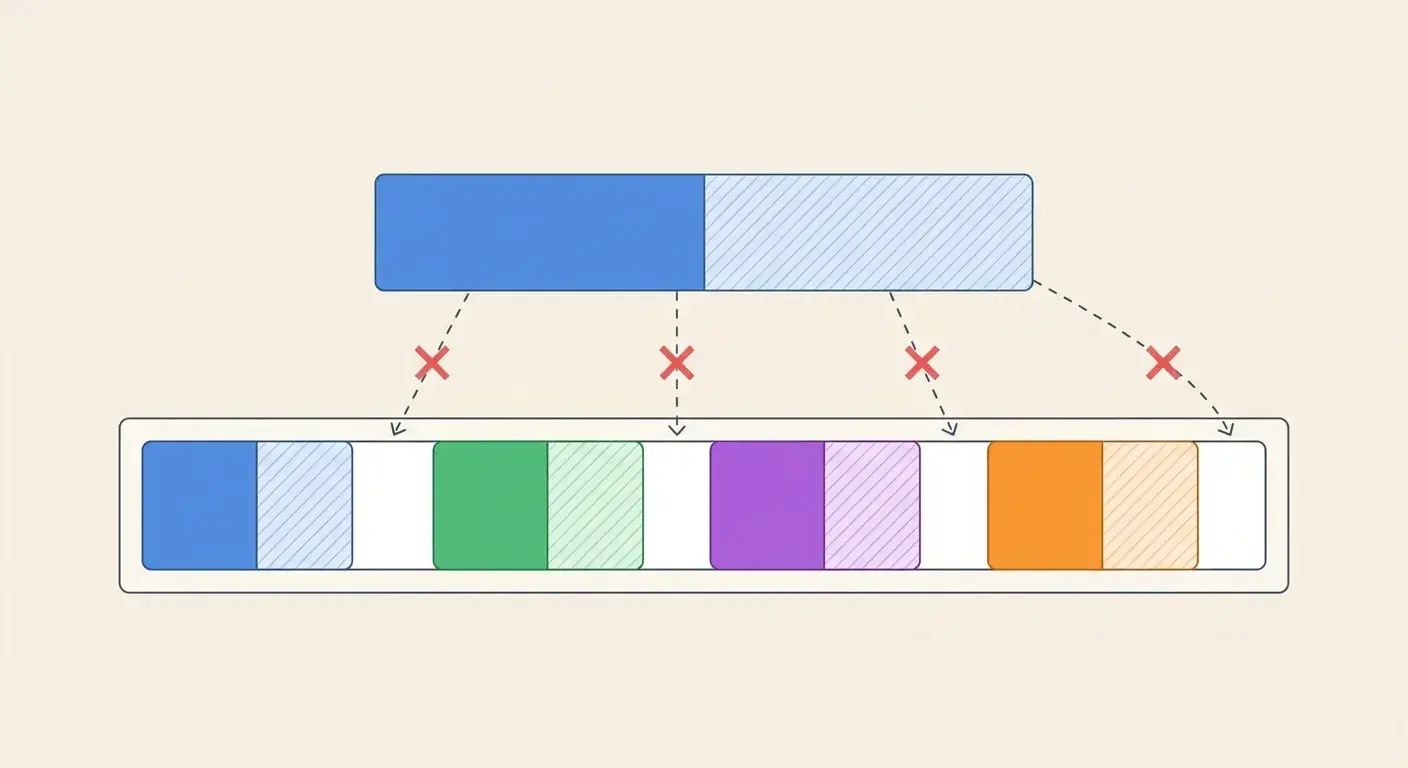
PagedAttention 是什么?从 OS 分页机制看懂 vLLM 的吞吐量优化
2026年5月26日 52 次浏览
-

WSL下启动的VSCode,Cline、Roo code等插件无法访问网络的问题
2026年5月12日 101 次浏览
-

-

2023年6月23日 165 次浏览
-
2016年12月24日 1,658 次浏览