

自制操作系统(18):用户态 malloc/free,解析ELF
我们的进程居然不支持malloc堆空间!这导致我们现在还在栈空间上读取程序映像…
这样做的话,后面稍微大一点的程序跑起来,栈空间就危险了。我们还是需要给进程做一个堆空间。
在PCB中记录堆的指针
首先,我们在PCB中加入两个字段来追踪堆的状态:
typedef struct PCB {
pid_t pid;
uintptr_t esp;
uintptr_t cr3;
uint32_t saved_eflags;
// 该任务的内核栈底(用于释放内存)
void* kernel_stack_bottom;
uintptr_t heap_start; // 堆起始地址(固定不变)
uintptr_t heap_break; // 当前堆顶(sbrk 移动这个)
uint16_t priority;
uint16_t quota;
uint32_t create_time;
PCB* prev = nullptr;
PCB* next = nullptr;
pid_t parent_pid;
uint8_t to_exit;
int exit_code;
process_state state;
process_queue waiting_queue;
file_description fd[MAX_FD_NUM];
uint32_t fd_num;
char cwd[256];
} PCB;
对于创建进程时初始化这两个值的逻辑,目前我们只能用代码区的起始地址加上代码大小来计算堆的起始位置:
pid_t create_user_process(void* code, uint32_t code_size, uint8_t priority, int argc, char** argv) {
...
vmm_switch(pd_addr);
uint32_t pages_needed = (code_size + 4095) / 4096;
for (uint32_t i = 0; i < pages_needed; i++) {
void* phys = pmm_alloc(1);
vmm_map_page((uintptr_t)phys, CODE_SPACE_ADDR + i * 4096, 6);
}
memcpy((void*)CODE_SPACE_ADDR, code_buf, code_size);
kfree(code_buf);
...
new_process->heap_start = (CODE_SPACE_ADDR + code_size + 0xFFF) & ~0xFFF; // 页对齐
new_process->heap_break = new_process->heap_start; // 一开始堆空间大小是0
...
}
sbrk系统调用
sbrk是set break的意思。break是Linux里面对于代码数据段结尾的术语,每次调用sbrk,就会增量地增加堆的空间。
sbrk的逻辑很简单:接受一个增量值,由于内核pmm是按页来分配内存的,如果当前的增量加上break没有超出同一页的边界(通过地址的掩码是否相等来判断),那就只把break增加增量即可;如果超出了边界,就按需申请新的页并做映射。
也就是说,实际上用户态可以超出break的边界一点点——因为申请的单位是一整个页,只要别超出申请页带来的余量就没问题(但是别这样做!)。
// SBRK(ebx = increment)
uintptr_t sys_sbrk(interrupt_frame* reg) {
uintptr_t increment = static_cast<uintptr_t>(reg->ebx);
PCB* cur_pcb = process_list[cur_process_id];
uintptr_t old_break = cur_pcb->heap_break;
uintptr_t new_break = old_break + increment;
if (new_break < cur_pcb->heap_start) return (uintptr_t)-1;
if (increment > 0) {
uintptr_t old_page = (old_break + 0xFFF) & ~0xFFF;
uintptr_t new_page = (new_break + 0xFFF) & ~0xFFF; // 按页对齐
for (uintptr_t addr = old_page; addr < new_page; addr += 0x1000) {
if (vmm_get_mapping(addr) == 0) {
uintptr_t phys = reinterpret_cast<uintptr_t>(pmm_alloc(0x1000));
vmm_map_page(phys, addr, 0x7); // Present | RW | User
}
}
}
cur_pcb->heap_break = new_break;
return old_break;
}
用户态侧的封装非常简单:
void* sbrk(uintptr_t increment) {
return (void*)syscall1((uintptr_t)SYSCALL::SBRK, increment);
}
malloc/free
还记得我们之前实现的kmalloc/kfree吗?其实我们可以把kheap的代码直接迁移到用户态!只需要把kheap_alloc_pages换成sbrk系统调用罢了。来对比一下两边的代码:
// ===== 用户态 =====
void heap_expand(block_t last_block, uint32_t need_size) {
uint32_t alloc_bytes = (need_size + 8 + 4095) & ~4095;
void* result = sbrk(alloc_bytes);
if ((int)result == -1) return;
block_t new_block = last_block + block_size(last_block) / 4 + 2;
set_block_size(new_block, alloc_bytes - 8);
block_free_mark(new_block);
heap_size += alloc_bytes;
set_epilogue((uint32_t*)heap_head - 1);
}
// ===== 内核态 =====
void kheap_expand(free_block block, uint32_t size) {
uint32_t alloc_pages = (size + 8 + 4095) / 4096;
free_block new_block = block + block_size(block) / 4 + 2; // 指向epilogue
kheap_alloc_pages(alloc_pages, 0x3);
set_block_size(new_block, alloc_pages * 4096 - 8);
block_free(new_block);
heap_size += alloc_pages;
set_epilogue();
}
// ===== 用户态 =====
void heap_init() {
uint32_t init_bytes = 4096;
uint32_t* base = (uint32_t*)sbrk(init_bytes);
if ((int)base == -1) return;
heap_size = init_bytes;
set_prologue(base);
heap_head = base + 1;
set_block_size(heap_head, init_bytes - 4 * 4);
block_free_mark(heap_head);
set_epilogue(base);
}
// ===== 内核态 =====
void kheap_init() {
heap_size = heap_initial_size;
kheap_head = reinterpret_cast<free_block>(kheap_alloc_pages(heap_initial_size, 0x3));
set_prologue();
++kheap_head;
set_block_size(kheap_head, heap_initial_size * 4096 - 4 * 4); // 头尾两个4字节的对称的块描述结构,记录块大小和是否已分配的信息
block_free(kheap_head);
set_epilogue();
return;
}
这些代码不能说非常相像,简直就是一模一样…
在Shell中使用堆空间
有了malloc/free这么好的东西,当然要先给我们的shell用上。之前程序映像是读取到栈空间的,现在我们改用堆空间:
bool try_exec(const char* cmd, int argc, char* argv[]) {
char fn[MAX_PATH];
file_stat fst;
for (int i = 0; i < 2; ++i) {
snprintf(fn, sizeof(fn), "%s%s", PATH[i], cmd);
if (stat(fn, &fst) == -1) continue;
int fd = open(fn, 1);
if (fd == -1) continue;
char* buffer = (char*)malloc(fst.size);
if (!buffer) {
close(fd);
continue;
}
int size = read(fd, buffer, fst.size);
close(fd);
if (size <= 0) {
free(buffer);
continue;
}
int child_pid = exec(buffer, size, 1, argc, argv);
free(buffer);
int ret = waitpid(child_pid);
return true;
}
return false;
}
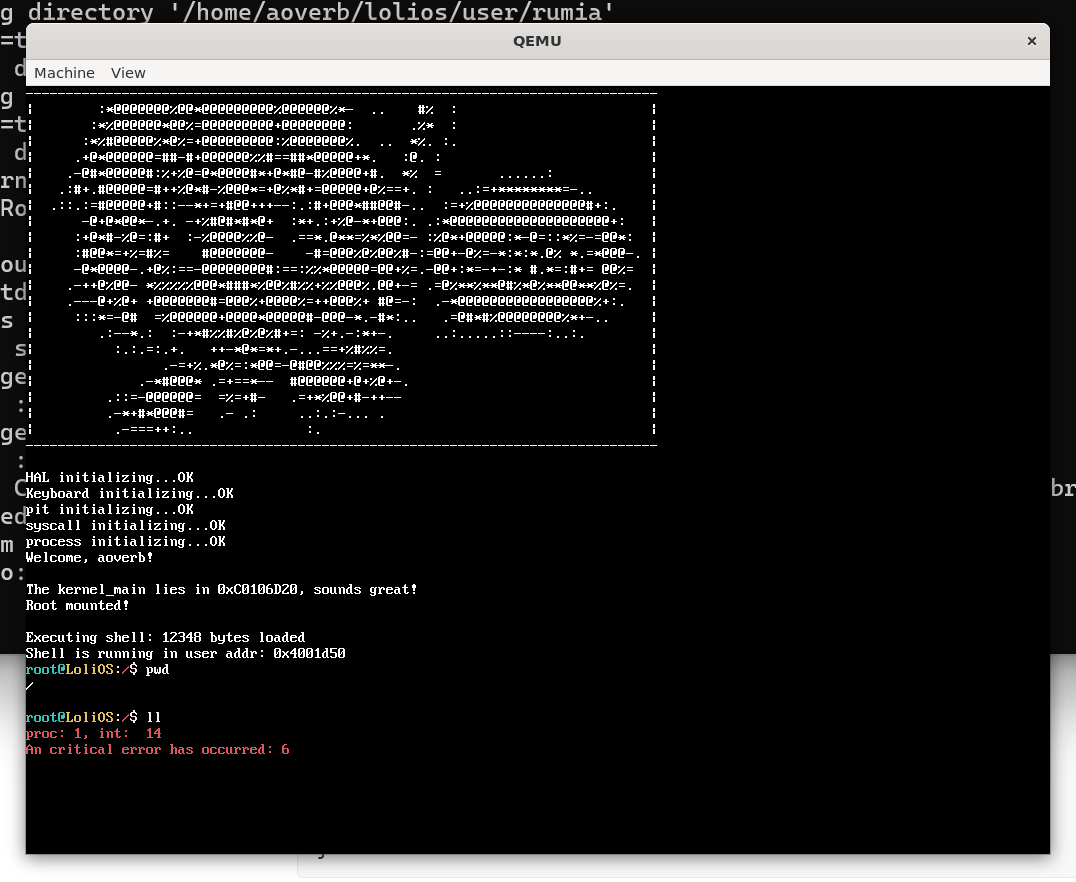
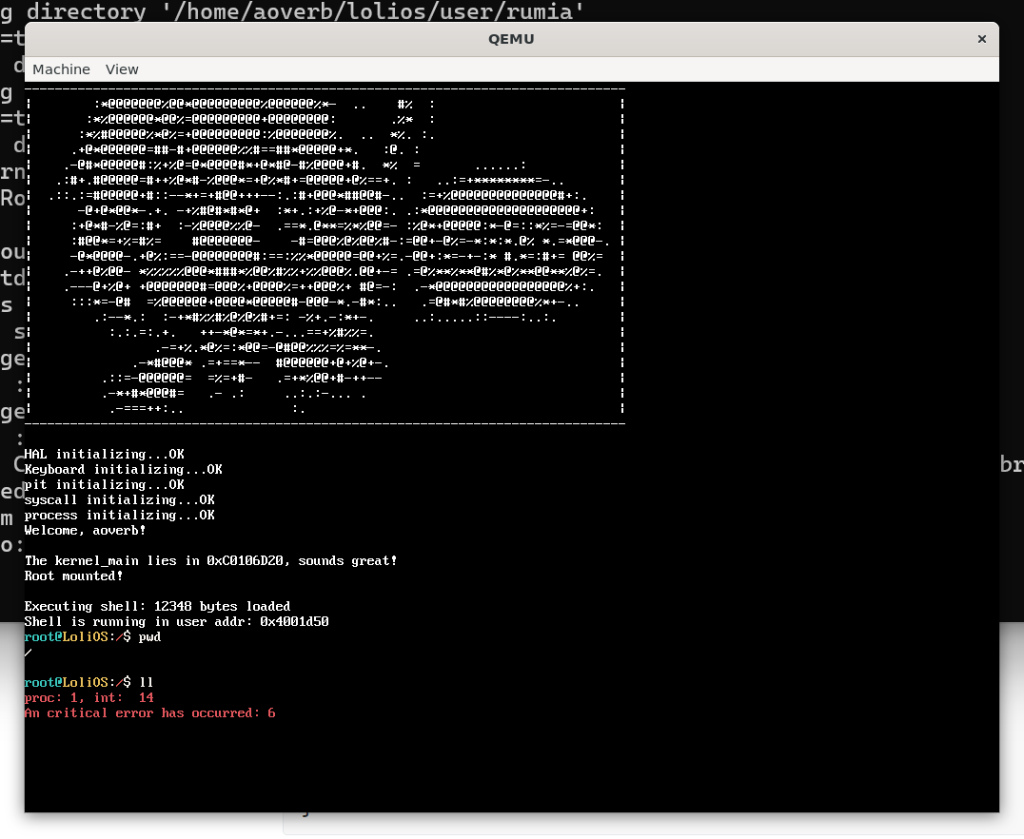
结果pwd可以,ll跪了…
大小超过4096的全部跪了。一通排查后发现,由于我们现在还在flat binary阶段,没有正确清零.bss段,记录堆的全局变量就变成了一堆垃圾值。不过由于我们下一节就要实现读取ELF了,先让AI帮我们生成一个临时方案——多分配几页去清空.bss段。
解析ELF
我们苦flat binary久矣,是时候迁移到ELF了!
ELF文件结构
ELF 文件
┌─────────────────────────┐
│ ELF Header │ ← 总入口,描述文件基本信息
├─────────────────────────┤
│ Program Header Table │ ← 给【加载器】看的目录(段/Segment)
├─────────────────────────┤
│ │
│ .text .rodata .data │ ← 实际的数据块
│ .bss .symtab ... │
│ │
├─────────────────────────┤
│ Section Header Table │ ← 给【链接器】看的目录(节/Section)
└─────────────────────────┘
ELF文件大体由以上四个部分组成:
ELF Header:一个固定大小的头,描述ELF的基本信息。
Program Header Table(段):描述了一系列的指令,告诉加载器要怎么加载数据块里面的内容,或者提供一些别的信息(比如动态链接相关的东西)。
数据块:实际的代码和数据。
Section Header Table(节):对数据块进行更细粒度的分块描述,本质是给链接器看的,我们不关心。
也就是说,上下的这两个Table,不太准确地说,就是描述同一块数据的不同视角。(要较真的话,两者描述的数据并不完全一致——段会有一些元数据包含在自己的头里,这些也需要被加载进去;而节会描述一些不会被加载到内存的内容,这些东西没有对应的加载segment。)
对比Flat Binary
那么相比于加载Flat Binary,加载ELF还需要些什么呢?
Flat Binary:binary除了指令流没有任何多余信息,把它按照大小加载到哪,就从哪作为入口点开始执行。
ELF:我们除了要解析ELF Header来判断这是不是一个合法的ELF,还得解析程序头表——因为它描述了一系列指令:把数据块的什么地方加载到哪(这样的加载会有若干个),可能还得清零一部分内存(.bss),最后跳转到读取的入口点。
加载ELF
我们现在只讨论加载ET_EXEC的ELF,不涉及ASLR(地址空间布局随机化),更不涉及PIC(位置无关代码)。
第一步:拆解create_user_process
我们的create_user_process函数实现达到了100+行,这不是一个好迹象,我们必须先拆解它。
这个函数现在的工作流是:为用户进程创建新的用户空间→复制镜像信息到内核缓冲区→切换页表→构造代码区并在新的用户空间映射→构造用户栈并在新的用户空间映射→初始化PCB(构造内核栈与iret栈帧)→将新进程加入就绪队列→切回页表。
我们以此为思路来抽取几个函数,新建一个包装这个流程的函数,称为exec:
pid_t exec(void* code, uint32_t code_size, uint8_t priority, int argc, char** argv);
这样的话我们甚至可以先改一下几个用到了create_user_process的地方:
// EXEC(ebx = code, ecx = code_size, edx = priority, esi = argc, ebp = argv)
int sys_exec(interrupt_frame* reg) {
void* code = reinterpret_cast<void*>(reg->ebx);
uint32_t code_size = reg->ecx;
uint8_t priority = static_cast<uint8_t>(reg->edx);
int argc = static_cast<int>(reg->esi);
char** argv = reinterpret_cast<char**>(reg->ebp);
return static_cast<int>(exec(code, code_size, priority, argc, argv)); // 改成了exec
}
// kernel_main
...
char* buffer = (char*)kmalloc(65536);
int size = v_read(cur_pcb, fd, buffer, 65536);
printf("Executing shell: %d bytes loaded\n", size);
pid_t shell_pid = exec(buffer, size, 1, 0, nullptr); // 改成了exec
waitpid(shell_pid);
while (1) {
yield();
}
毕竟create_user_process的逻辑其实更像exec,我们先给它改头换面,再一步步抽取:
pid_t exec(void* code, uint32_t code_size, uint8_t priority, int argc, char** argv) {
uint32_t saved_eflags = spinlock_acquire(&process_list_lock);
pid_t newpid = get_new_pid();
if (newpid == 0) {
spinlock_release(&process_list_lock, saved_eflags);
return 0;
}
void* code_buf = copy_image_to_kernel_buffer(code, code_size);
uint32_t* arg_lens;
char** arg_bufs;
copy_args_to_kernel_buffer(argc, argv, arg_lens, arg_bufs);
uint32_t pd_addr_old = vmm_get_cr3();
uint32_t pd_addr = vmm_create_page_directory();
asm volatile ("cli");
vmm_switch(pd_addr);
copy_image_from_kernel_buffer(code_buf, code_size);
uintptr_t sp = create_user_stack(USER_STACK_PAGE_SIZE);
construct_args_for_user_stack(argc, arg_lens, arg_bufs, sp);
PCB* new_pcb = init_pcb(newpid);
prepare_pcb_for_new_process(new_pcb);
new_pcb->cr3 = pd_addr;
// heap_start 也要考虑 .bss 额外页
uint32_t total_pages = calc_total_pages(code_size);
new_pcb->heap_start = CODE_SPACE_ADDR + total_pages * 4096;
new_pcb->heap_break = new_pcb->heap_start;
init_kernel_stack(new_pcb, KERNEL_STACK_SIZE, sp, CODE_SPACE_ADDR);
insert_into_scheduling_queue(newpid, priority);
vmm_switch(pd_addr_old);
spinlock_release(&process_list_lock, saved_eflags);
asm volatile ("sti");
return newpid;
}
第二步:将Flat Binary加载替换为ELF解析
重构完之后,我们就可以在exec函数中替换原来flat binary的加载逻辑了。
原来的逻辑是:直接把flat binary拷到CODE_SPACE_ADDR上,后面再垫几页零数据,再在后面构建栈。
ELF的逻辑是:删掉CODE_SPACE_ADDR这个硬编码,读取ELF文件中的Segment段,遇到PT_LOAD指令就按要求从数据块里拷贝内容到用户区,并按要求映射虚拟地址。
改动后的exec函数:
pid_t exec(void* code, uint32_t code_size, uint8_t priority, int argc, char** argv) {
uint32_t saved_eflags = spinlock_acquire(&process_list_lock);
pid_t newpid = get_new_pid();
if (newpid == 0) {
spinlock_release(&process_list_lock, saved_eflags);
return 0;
}
首先一上来会有一个验证ELF镜像是否有效的逻辑,无效直接退出:
if (!verify_elf(code, code_size)) {
return 0;
}
接着,我们仍然需要把镜像拷贝到内核缓冲区(因为切换页表后原来的用户空间就不可见了),但不再需要从内核缓冲区拷贝到固定的用户空间地址——取而代之的是在内核缓冲区直接解析ELF:
void* code_buf = copy_image_to_kernel_buffer(code, code_size);
uint32_t* arg_lens;
char** arg_bufs;
copy_args_to_kernel_buffer(argc, argv, arg_lens, arg_bufs);
uint32_t pd_addr_old = vmm_get_cr3();
uint32_t pd_addr = vmm_create_page_directory();
asm volatile ("cli");
vmm_switch(pd_addr);
// 不再是简单的复制,而是解析ELF并构造用户空间
uint32_t entry = 0;
uint32_t heap_addr = 0;
if (!construct_user_space_by_elf_image(code_buf, code_size, entry, heap_addr)) {
kfree(code_buf);
vmm_switch(pd_addr_old);
asm volatile ("sti");
spinlock_release(&process_list_lock, saved_eflags);
// todo: dispose_user_space(pd_addr);
return 0;
}
kfree(code_buf);
construct_user_space_by_elf_image会返回两个关键值:入口点地址entry和堆起始地址heap_addr。堆起始地址的计算方式是:记录所有PT_LOAD段实际占用地址的最大值,然后进行页对齐。
如果解析失败,除了返回还要销毁用户空间,这里我们先记录todo(后面就能修复了!)。
后面的修改点有两个:一是我们有了ELF指定的entry,不再使用固定的用户空间开头地址;二是可以直接将ELF解析器给出的堆空间地址赋给PCB:
uintptr_t sp = create_user_stack(USER_STACK_PAGE_SIZE);
construct_args_for_user_stack(argc, arg_lens, arg_bufs, sp);
PCB* new_pcb = init_pcb(newpid);
prepare_pcb_for_new_process(new_pcb);
new_pcb->cr3 = pd_addr;
new_pcb->heap_start = heap_addr;
new_pcb->heap_break = heap_addr;
init_kernel_stack(new_pcb, KERNEL_STACK_SIZE, sp, entry);
insert_into_scheduling_queue(newpid, priority);
vmm_switch(pd_addr_old);
spinlock_release(&process_list_lock, saved_eflags);
asm volatile ("sti");
return newpid;
}
剩下的就是实现verify_elf和construct_user_space_by_elf_image这两个函数了。
验证ELF:verify_elf
verify_elf负责检查魔数、文件类型、目标架构和边界:
int verify_elf(void* elf_image, uint32_t size) {
if (!elf_image || size < sizeof(Elf32_Ehdr))
return 0;
Elf32_Ehdr* ehdr = (Elf32_Ehdr*)elf_image;
if (ehdr->e_ident[EI_MAG0] != ELFMAG0 ||
ehdr->e_ident[EI_MAG1] != ELFMAG1 ||
ehdr->e_ident[EI_MAG2] != ELFMAG2 ||
ehdr->e_ident[EI_MAG3] != ELFMAG3)
return 0;
if (ehdr->e_ident[EI_CLASS] != ELFCLASS32)
return 0;
if (ehdr->e_ident[EI_DATA] != ELFDATA2LSB)
return 0;
if (ehdr->e_ident[EI_VERSION] != EV_CURRENT)
return 0;
if (ehdr->e_type != ET_EXEC && ehdr->e_type != ET_REL) // 不支持重定向
return 0;
if (ehdr->e_machine != EM_386) // x86
return 0;
if (ehdr->e_ehsize != sizeof(Elf32_Ehdr)) // Elf Header大小
return 0;
if (ehdr->e_phoff + ehdr->e_phnum * sizeof(Elf32_Phdr) > size) // 越界检查
return 0;
return 1;
}
我们不关心Section Header Table,所以没有对节的边界进行检查。
加载ELF到用户空间:construct_user_space_by_elf_image
加载ELF到用户空间的步骤是:
- 按照ELF文件头的描述,找到段表的开头和边界;
- 遍历Program Header,逐个解析段;
- 遇到类型为PT_LOAD的段,就按照其指引把数据块中对应的部分复制到指定的虚拟地址;
- 直到遍历完所有段。
#define VMM_PAGE_PRESENT (1 << 0) /* P: 位 0,1 表示页面在内存中 */
#define VMM_PAGE_WRITABLE (1 << 1) /* R/W: 位 1,1 表示可读写,0 表示只读 */
#define VMM_PAGE_USER (1 << 2) /* U/S: 位 2,1 表示用户态可访问,0 表示仅内核 */
uint32_t elf_to_vmm_flags(uint32_t p_flags) {
uint32_t vmm_flags = VMM_PAGE_PRESENT | VMM_PAGE_USER;
if (p_flags & PF_W) vmm_flags |= VMM_PAGE_WRITABLE;
return vmm_flags;
}
int construct_user_space_by_elf_image(void* elf_image, uint32_t size, uint32_t& entry, uint32_t &heap_addr) {
Elf32_Ehdr* ehdr = (Elf32_Ehdr*)elf_image;
// 我们始终假设在调用此函数之前,已经调用了verify_elf进行检查
// 1. 按照ELF文件头的描述,找到段的开头和边界
Elf32_Phdr* phdr = (Elf32_Phdr*)((uint32_t)elf_image + ehdr->e_phoff);
uint16_t phnum = ehdr->e_phnum;
heap_addr = 0;
// 2. 用Program Header遍历解析段数据
for (uint32_t i = 0; i < phnum; ++i) {
phdr = (Elf32_Phdr*)((uint32_t)elf_image + ehdr->e_phoff + i * ehdr->e_phentsize);
if (phdr->p_type != PT_LOAD) continue;
if (phdr->p_offset + phdr->p_filesz > size) {
// todo: 需要回收已映射的内存
return 0;
}
// 3. 解析到PT_LOAD段,按照指引复制数据到指定地址
// 映射页要求物理地址和虚拟地址都按页对齐
// 物理地址无所谓(我们自己分配),但ELF提供的虚拟地址不一定按页对齐
// 所以需要确认每一块虚拟地址的起始和终点,做页对齐
uintptr_t aligned_load_vaddr = phdr->p_vaddr & ~0xFFF;
uintptr_t aligned_load_vaddr_end = (phdr->p_vaddr + phdr->p_memsz + 0xFFF) & ~0xFFF;
uint32_t load_size = aligned_load_vaddr_end - aligned_load_vaddr;
void* load_paddr = elf_malloc(load_size);
uint32_t load_flag = elf_to_vmm_flags(phdr->p_flags);
for (uintptr_t offset = 0; offset < load_size / 0x1000; ++offset) {
elf_mmap((uintptr_t)load_paddr + offset * 0x1000, aligned_load_vaddr + offset * 0x1000, load_flag);
}
memcpy((void*)phdr->p_vaddr, (void*)((uint32_t)elf_image + phdr->p_offset), phdr->p_filesz);
// p_filesz < p_memsz 意味着存在.bss段,需要手动置零
if (phdr->p_filesz < phdr->p_memsz) {
memset((void*)((uint32_t)phdr->p_vaddr + phdr->p_filesz), 0, phdr->p_memsz - phdr->p_filesz);
}
// 记录所有PT_LOAD段占用的最高地址,用于确定堆起始位置
heap_addr = heap_addr < aligned_load_vaddr_end ? aligned_load_vaddr_end : heap_addr;
}
entry = ehdr->e_entry;
return heap_addr > 0 ? 1 : 0;
}
调试ELF加载器
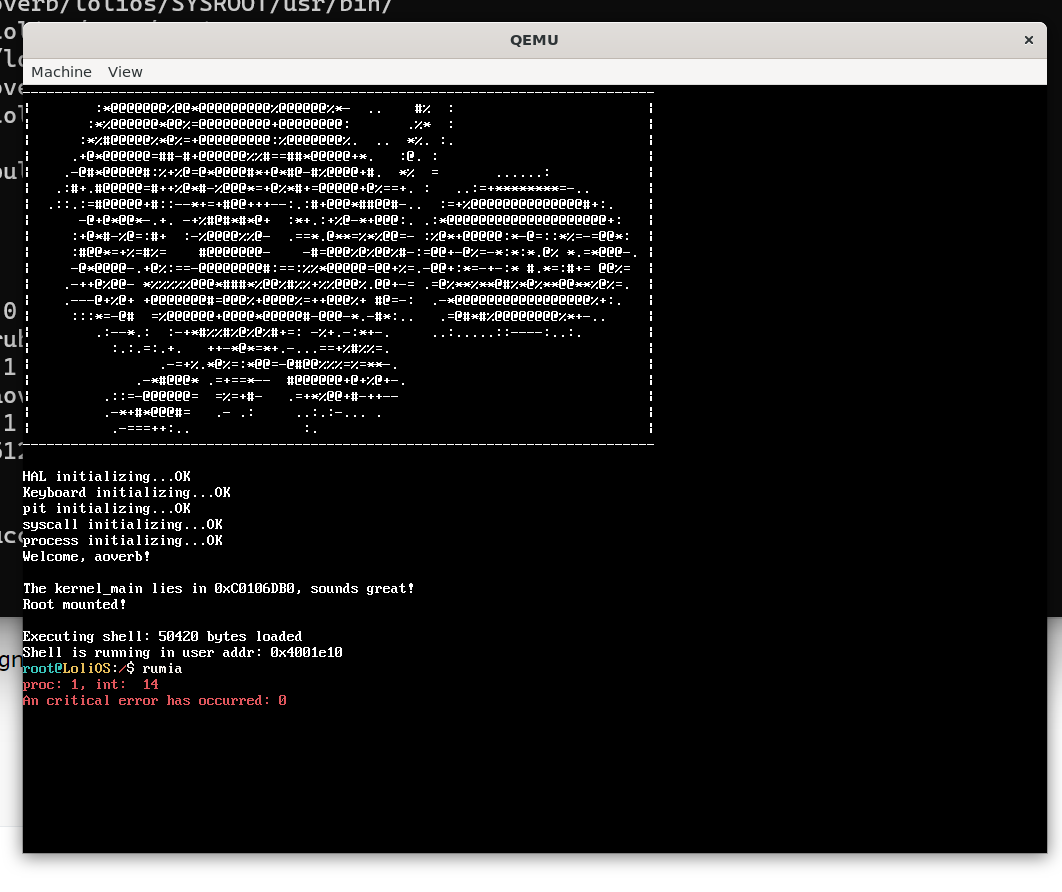
shell正常打开了,但一执行程序就跪了。为什么捏…
回头看exec函数的代码:
pid_t exec(void* code, uint32_t code_size, uint8_t priority, int argc, char** argv) {
...
if (!verify_elf(code, code_size)) {
return 0;
}
// 待会我们直接在内核缓冲区解析ELF,不需要复制
// void* code_buf = copy_image_to_kernel_buffer(code, code_size);
这里有问题!”不用从内核再拷贝到用户空间”不等于”不用拷贝到内核”。切换页表后原来的用户空间就不可见了,镜像数据还是需要先拷贝到内核缓冲区的。修复后:
void* code_buf = copy_image_to_kernel_buffer(code, code_size);
...
if (!construct_user_space_by_elf_image(code_buf, code_size, entry, heap_addr)) {
kfree(code_buf);
vmm_switch(pd_addr_old);
asm volatile ("sti");
spinlock_release(&process_list_lock, saved_eflags);
return 0;
}
kfree(code_buf);
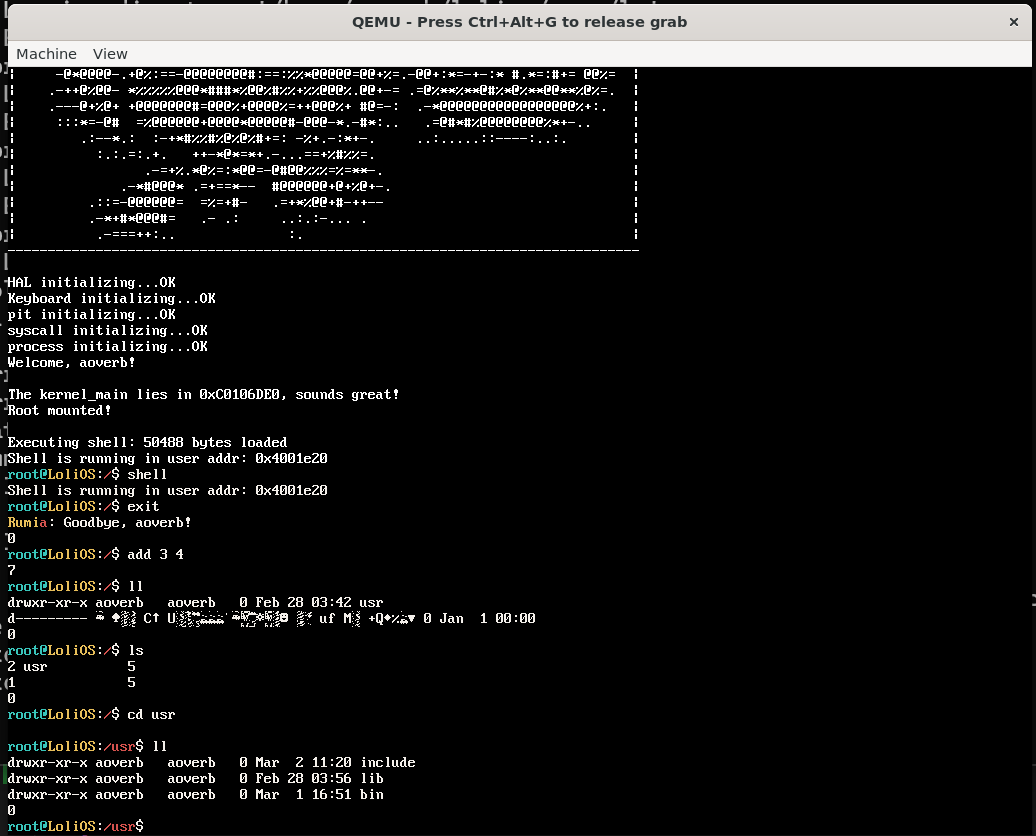
修复这个BUG之后,我们的ELF加载器正确运行了!用户态程序也回来了!
总结
经此一役,我们利用新实现的malloc/free,总算是抛弃了落后的flat binary,投向了ELF的怀抱!
下一节我们来看看IPC(进程间通信),来实现管道吧!
参与讨论
(Participate in the discussion)
参与讨论
没有发现评论
暂无评论