

今天我们来用5090来对两种推理平台跑一次性能测试。我们会测量两种推理框架在4090上加载Qwen2.5-7B,相同无关参数的情况下,控制prefill和decode量和并发量,测量各自的吞吐量和p99延迟。
然而,尽可能公平地测试vLLM、SGLang并不是一件易事,我们来看看要怎么做到这些。
vLLM、SGLang介绍
vLLM、SGLang是两套不同的推理框架,下面介绍两者的异同点:
相同的地方:两套引擎共享两个核心思想:continuous batching和pagedAttention。
不同的地方就多了:
两者有不同的前缀缓存策略:vLLM是块级哈希,而SGLang的RadixAttention则是用基数树来进行前缀匹配;
两者有不同的推理核,如vLLM有flashAttention,SGLang有FlashInfer;
两者在迭代推进、组批上有不同的调度策略。
公平保证
所谓的公平保证,实际上是尽可能去消除两者的不同的地方,用一样的配置和条件进行测试。
不同点的消除
对于不同的前缀缓存策略这点,我们可以各自配置参数去开关前缀缓存,各测一组数据;
而两者不同的推理核和调度策略,这是引擎性能的一部分,没有办法消除,只能记录两者各用了什么。
配置的一致
对于关键参数,我们各自调整至一致,如一样的chunked prefill块大小、上下文长度、服务端与客户端并发数量,prefill和decode的token数量;
我们不对KV-Cache进行约束,通过控制token数量和并发数,来保证KV-Cache吃不满显存,不会成为各自的瓶颈和差异点;
我们使用同样的硬件环境、同样参数大小、dtype一致的大模型来进行测试;
我们使用同一个压测器,只替换对应两个引擎的,不同的API地址来进行测试。
vLLM vs SGLang 性能实测4090、Qwen2.5-7B、吞吐与 p99 延迟
测试工具
Claude生成的压测脚本,包含环境配置的setup.sh,运行压测的orchestrate.py,保存压测配置的config.yaml,生成结果图表的plot.py。
测试过程
在本地的3060ti跑通过只带vllm的config,再到AutoDL平台上租卡运行。
本来是想用4090卡的,不好租,只好租了5090.先用无卡模式搭建好环境。
下载巨慢,耐心等待…
环境配置好后关机,转有卡。
原来的机子没卡了,而即使使用复制实例,也没卡可用…直到过了一个小时后。大家尽量错峰测试。
参考的启动日志:
VLLM_ATTENTION_BACKEND=FLASH_ATTN VLLM_USE_FLASHINFER_SAMPLER=0 VLLM_FLASH_ATTN_VERSION=2 vllm serve /root/autodl-tmp/Qwen2.5-7B-Instruct --max-model-len 4096 --gpu-memory-utilization 0.9 --max-num-seqs 64 --max-num-batched-tokens 2048 --no-enable-prefix-caching --port 8000
(EngineCore pid=3226) INFO 06-03 16:04:33 [cuda.py:378] Using FLASH_ATTN attention backend out of potential backends: ['FLASH_ATTN', 'FLASHINFER', 'TRITON_ATTN', 'FLEX_ATTENTION'].
(EngineCore pid=3226) INFO 06-03 16:04:33 [flash_attn.py:636] Using FlashAttention version 2
(EngineCore pid=3226) INFO 06-03 16:04:36 [default_loader.py:397] Loading weights took 2.81 seconds
(EngineCore pid=3226) INFO 06-03 16:04:36 [gpu_model_runner.py:5132] Model loading took 14.29 GiB memory and 3.527771 seconds
(EngineCore pid=3226) INFO 06-03 16:04:38 [backends.py:1089] Using cache directory: /root/.cache/vllm/torch_compile_cache/f3636648d7/rank_0_0/backbone for vLLM's torch.compile
(EngineCore pid=3226) INFO 06-03 16:04:38 [backends.py:1148] Dynamo bytecode transform time: 1.74 s
(EngineCore pid=3226) INFO 06-03 16:04:39 [backends.py:292] Directly load the compiled graph(s) for compile range (1, 2048) from the cache, took 0.766 s
(EngineCore pid=3226) INFO 06-03 16:04:39 [decorators.py:311] Directly load AOT compilation from path /root/.cache/vllm/torch_compile_cache/torch_aot_compile/c96283b3ebfbb18205effb2c30610139aff794d92ae8716d3015fe38a6395424/rank_0_0/model
(EngineCore pid=3226) INFO 06-03 16:04:39 [monitor.py:53] torch.compile took 2.70 s in total
(EngineCore pid=3226) INFO 06-03 16:04:39 [monitor.py:81] Initial profiling/warmup run took 0.15 s
(EngineCore pid=3226) INFO 06-03 16:04:46 [gpu_model_runner.py:6279] Profiling CUDA graph memory: PIECEWISE=19 (largest=128), FULL=11 (largest=64)
(EngineCore pid=3226) INFO 06-03 16:04:47 [gpu_model_runner.py:6365] Estimated CUDA graph memory: 0.13 GiB total
(EngineCore pid=3226) INFO 06-03 16:04:47 [gpu_worker.py:466] Available KV cache memory: 13.34 GiB
(EngineCore pid=3226) INFO 06-03 16:04:47 [gpu_worker.py:481] CUDA graph memory profiling is enabled (default since v0.21.0). The current --gpu-memory-utilization=0.9000 is equivalent to --gpu-memory-utilization=0.8959 without CUDA graph memory profiling. To maintain the same effective KV cache size as before, increase --gpu-memory-utilization to 0.9041. To disable, set VLLM_MEMORY_PROFILER_ESTIMATE_CUDAGRAPHS=0.
(EngineCore pid=3226) INFO 06-03 16:04:47 [kv_cache_utils.py:1733] GPU KV cache size: 249,776 tokens
[launch] PATH=/usr/local/cuda/bin:/root/autodl-tmp/venv-sglang/bin:$PATH CUDA_HOME=/usr/local/cuda /root/autodl-tmp/venv-sglang/bin/python -m sglang.launch_server --model-path /root/autodl-tmp/Qwen2.5-7B-Instruct --host 127.0.0.1 --port 30000 --context-length 4096 --mem-fraction-static 0.9 --max-running-requests 64 --chunked-prefill-size 2048 --disable-radix-cache
attention_backend='flashinfer'[2026-06-03 17:16:45] INFO server_args.py:1835: Attention backend not specified. Use flashinfer backend by default.
[2026-06-03 17:16:56] Load weight end. elapsed=3.13 s, type=Qwen2ForCausalLM, dtype=torch.bfloat16, avail mem=16.41 GB, mem usage=14.30 GB.
[2026-06-03 17:16:56] Using KV cache dtype: torch.bfloat16
[2026-06-03 17:16:56] KV Cache is allocated. #tokens: 249719, K size: 6.67 GB, V size: 6.67 GB
[2026-06-03 17:16:56] Memory pool end. avail mem=3.05 GB
[2026-06-03 17:16:56] Capture cuda graph begin. This can take up to several minutes. avail mem=2.50 GB
里面有几个重点:vllm用的kernel是flashattention,KV-Cache大小占用249,776tokens;sglang用的是flashinfer,KV-Cache大小占用249,719tokens。单请求最多64×1024≈6.5 万 token,只占了1/4的KV池,做到了KV-Cache吃不满显存。
测试结果与分析
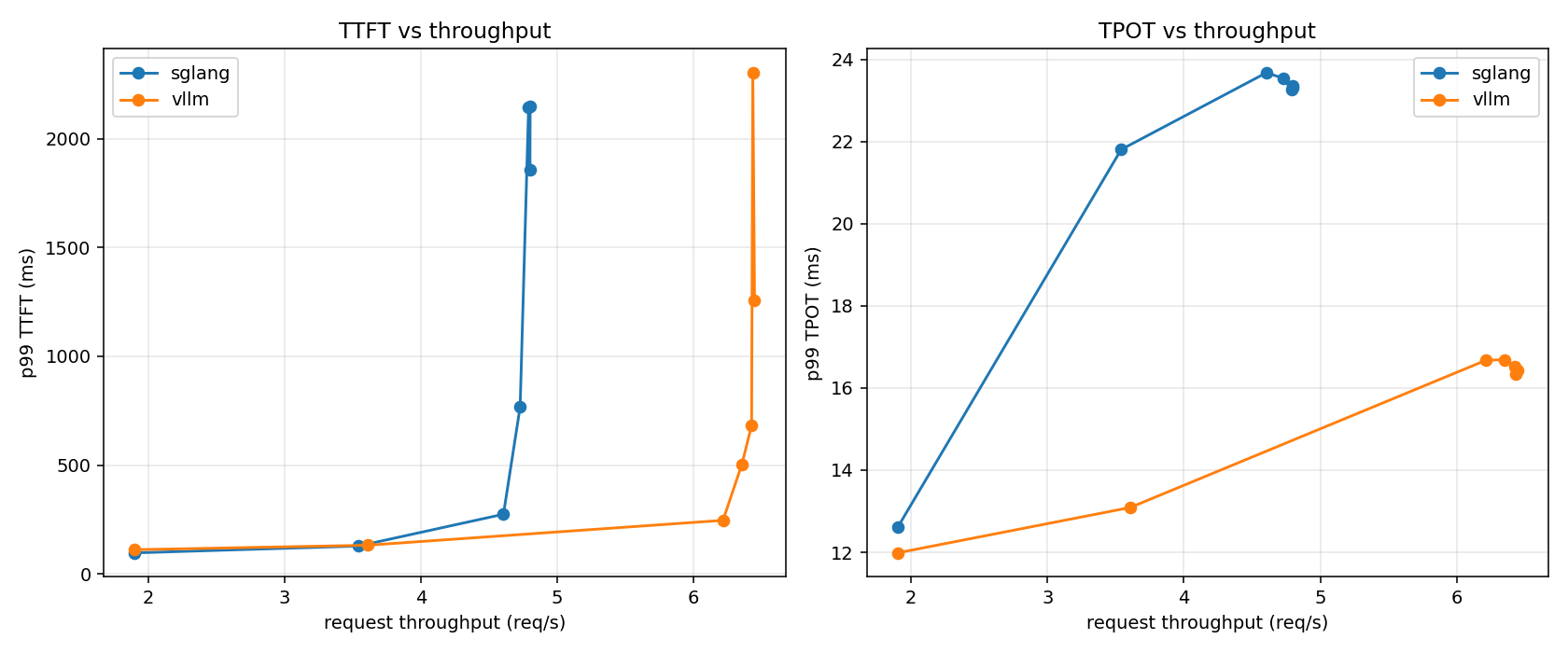
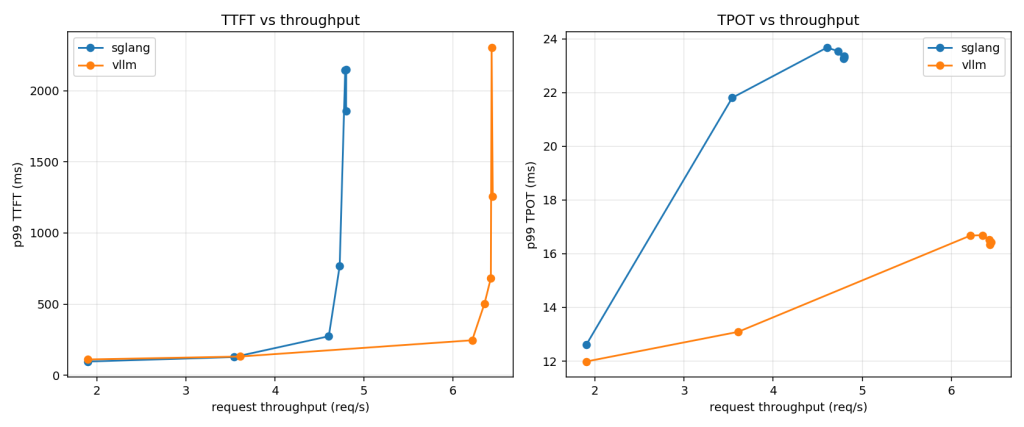
在上面给定的条件下,看TTFT,可以发现sglang的拐点(knee)出现在4.7req/s,而vllm出现在6.3req/s;在3.6req/s前,两者持平,而拐点后,sglang的TTFT一直都比vllm的要高;sglang实际能撑住的大概是4.8req/s,而vllm则在6.5req/s左右。
看TPOT,两者的差距要更大,sglang的TPOT一直比vllm的要高,随着并发数加大,总体来到两倍差距。
结论
在本次测试的设定下——关闭前缀缓存、无共享前缀的random负载,在5090单卡,in/out 512/512 定长、并发上限64的场景下——vLLM 在吞吐和 p99 延迟上都优于 SGLang。
具体来说:吞吐方面,vLLM 的拐点出现在约 6.3 req/s、能稳定撑到约 6.5 req/s,而 SGLang 的拐点在约 4.7 req/s、稳定吞吐约 4.8 req/s,vLLM 高出约 35%;在约 3.6 req/s 以下两者的 TTFT 基本持平(都在 100–270ms 量级),而过了拐点之后 SGLang 的 TTFT 明显先恶化。p99 TPOT 的差距更稳定:饱和处 vLLM 约 16.5ms、SGLang 约 23.5ms(约 1.4 倍),而且在相同吞吐下(SGLang 已接近饱和、vLLM 还很从容时)相对差距会更大,vLLM 的曲线整体也更平、退化更平缓。
但这个结论限定场景:这次benchmark关掉了前缀缓存、用的是无共享前缀的负载,而前缀复用(RadixAttention)恰恰是 SGLang 最大的卖点。也就是说,这组数据测的是“在 SGLang 最不擅长的场景下”的对比——在这个画像里 vLLM 更优,但这不代表在带共享前缀的真实负载下结论一样成立。这是一个可以延伸的点。
还有一个值得注意的点:这次两个引擎的 attention kernel 并没有对齐——vLLM 用的是 FlashAttention,SGLang 用的是 FlashInfer。因为vLLM 这边的 FlashInfer 在 5090 上 JIT 编译不通,而 SGLang 的 FA3 只支持 Hopper(sm90),两边能用的后端没有交集。所以这属于一个无法消除的差异。但我额外做了一个对照来判断它是不是主因:把 SGLang 自己的 attention 从 Triton 换成 FlashInfer,两条曲线几乎重合。这说明在本测试的负载下,attention kernel 的选择并不是性能的主要决定因素——也就是说:上面 vLLM 与 SGLang 的差距更可能来自引擎本身的调度策略,而非 attention kernel 的优劣。
另外,从启动日志可以确认 KV 池没有成为瓶颈:vLLM 报告的 KV 池为 249,776 tokens、SGLang 为 249,719 tokens。两者几乎一致;而单请求最大占用为 64×1024 ≈ 65,536 tokens,仅约池子的四分之一。两个引擎都有充足的 KV 余量,谁都没被显存压力逼进抢占/驱逐路径,所以这个差异是引擎行为,而不是显存配置造成的。
延伸的实验:可以针对开启前缀缓存、构造带共享前缀的负载,正面检验 RadixAttention(基数树前缀复用)能不能让 SGLang 在它擅长的场景里反超 vLLM。
实验相关代码+数据:
https://github.com/aoverb/vllm-vs-sglang-benchmark-tools
参与讨论
(Participate in the discussion)
参与讨论
发现2条评论
夏槿
2026年06月09日 05:38获取中...
不明觉厉...最近的画风变得硬核起来了
B分之A
博主2026年06月09日 15:54获取中...
@夏槿哈哈,偶尔还是要学点新东西,折腾下